@dan.t, I don't speak curl. Anyway you could translate that into something I could use with NR.
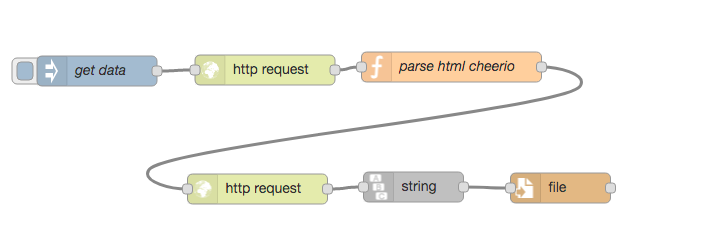
This is the relevant part of the flow I currently use.
[
{
"id": "4e1c7a5c.6f5574",
"type": "file",
"z": "a5638902.63e4a8",
"name": "Save File",
"filename": "",
"appendNewline": false,
"createDir": true,
"overwriteFile": "true",
"encoding": "none",
"x": 760,
"y": 740,
"wires": [
[]
]
},
{
"id": "358aebb5.0850d4",
"type": "inject",
"z": "a5638902.63e4a8",
"name": "Dev Hub Daily 4:00AM",
"topic": "",
"payload": "",
"payloadType": "date",
"repeat": "",
"crontab": "00 04 * * *",
"once": false,
"onceDelay": 0.1,
"x": 250,
"y": 740,
"wires": [
[
"6c262e2f.f4ddd"
]
]
},
{
"id": "6c262e2f.f4ddd",
"type": "http request",
"z": "a5638902.63e4a8",
"name": "Get backup",
"method": "GET",
"ret": "bin",
"paytoqs": false,
"url": "http://192.168.7.111/hub/backupDB?fileName=latest",
"tls": "",
"proxy": "",
"authType": "basic",
"x": 450,
"y": 740,
"wires": [
[
"271d56fe.3c61fa"
]
]
},
{
"id": "271d56fe.3c61fa",
"type": "string",
"z": "a5638902.63e4a8",
"name": "Get filename",
"methods": [
{
"name": "strip",
"params": [
{
"type": "str",
"value": "attachment; filename="
}
]
},
{
"name": "prepend",
"params": [
{
"type": "str",
"value": "\\\\mylocation"
}
]
}
],
"prop": "headers.content-disposition",
"propout": "filename",
"object": "msg",
"objectout": "msg",
"x": 610,
"y": 740,
"wires": [
[
"4e1c7a5c.6f5574"
]
]
}
]