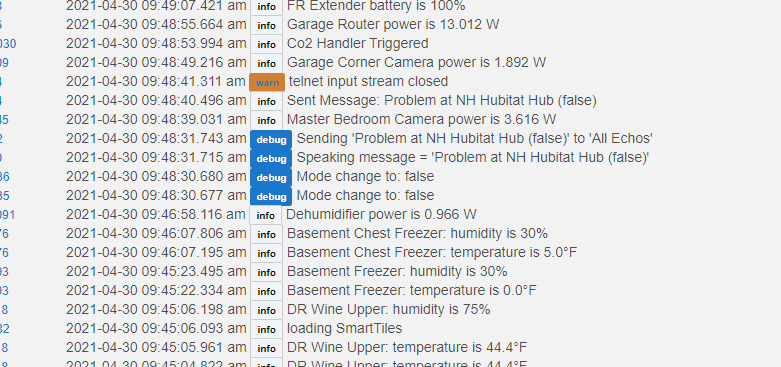
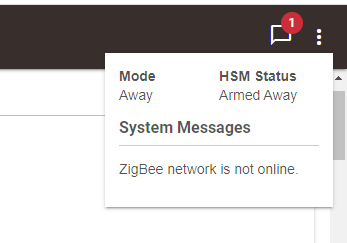
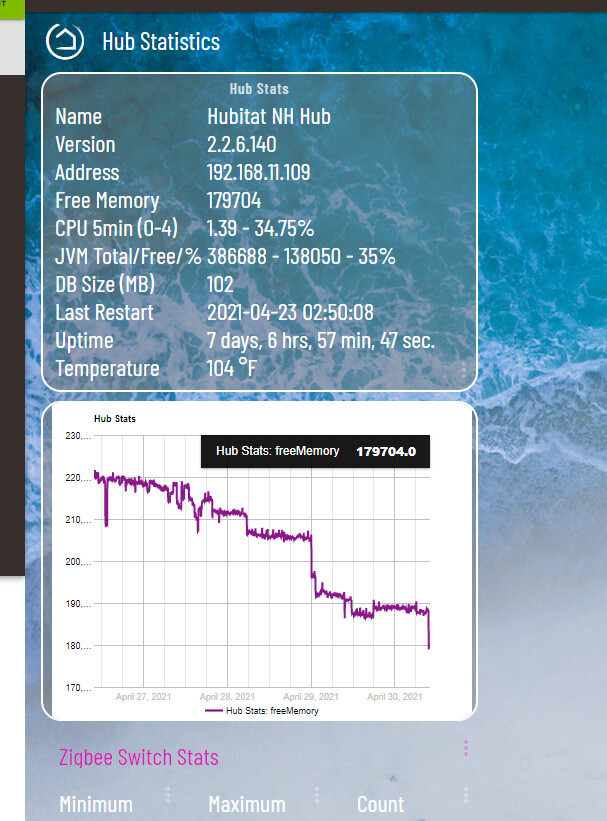
zigbee radio crashed.. nothing relavent in the logs.. just a weird rule saying via alexa and email "problem and nh hubitat (falsE). not sure where that even came from dont think i have any rule that would do that.. See attachments.. can someone from support poke at the logs.. if this is not a k nown issue?
Reboot fixed it. Low memory maybe as it has been going down over a week.
to rehash this is still occurring same problem in both my hubs in two locations. so leaning towards a bug in the firmware.. zwave intermiattantly crashes ..
The first thing that the hub shuts down if it's overheating or processing too hard, is to shut down the Zigbee radio. If you didn't do so already, I suggest to temporarily disable any custom drivers and apps, especially those using telnet or websocket. If your Zigbee continues to go offline, please send us an email at support@hubitat.com so we can further investigate.
If you don't know how to disable an app or a driver, please see "Disable Device Drivers" and "Disable Apps" sub-headings in the following documents:
Not going to work that is half my.apps and it follows.a.pattern if you want to.look at the hub a. 6-7 days up and it starts doing it.. maybe low memory .. a leak.somewhere. I will start grapjing CPU and temp to see if that is the issue. Could you add more info to the.logging stating why.it is shutting down the radio?
This started happening to me as well about a month ago. I’m pretty sure it’s related to low memory. The Zigbee radio shuts down after about 7 days. It was 4 days, but up to 7 after disabling Apple adaptive lighting via Homebridge on some of my lights. I still have around 20 enabled and another 50 through the Hue bridges. When the radio goes down, everything else still works fine. A reboot doesn’t really fix it. I have to do a full shut down and restart. Free memory was down to about 240 MB each time it happened.
In the end if the issue really is resource leaks, the only path forward is either to find which apps and drivers are leaking (typically by disabling them until you find the culprit) or to do scheduled reboots before the resources are exhausted.
If you're not willing to do A, you have to do B, or live with C which is the hub crashing.
If the issue is really overheating/high CPU usage or a defective hub, scheduled reboots aren't likely to help.
it could be inconvenient or tedious with that much of your own code running, but how can support be expected to ignore the possible contribution of custom code to the problem a user is reporting?
There's a big reason I run almost all my app and automation logic external from Hubitat.
Not because I couldn't run it on the hub - it is plenty capable of handling it - but rather I do it for portability, disaster recovery, and enhanced troubleshooting capabilities.
My zigbee hub used to do this about every 2 weeks. The only "non stock" app I have is hubconnect. The only "non stock" drivers are hub connect and hub information. The hub information driver was only recently so that I could monitor the memory level when it did crash. Found out it was usually below 400k. So now I use a flow in node red that when the hub information driver reports below 400k, to reboot the hub.
I did (what I call option B above - scheduled/triggered reboots) for quite a long time.
Now my memory drop rate is low enough (still drops though, and eventually the hub will slow down or crash) that I just do a reboot manually every month or so.
Thamks will monitor the memory and do a reboot. I know.it is not heat or cpu as I have monitored those in hub statistics. I also don't see any app or device in the stats constantly going up so I don't think it is a leak in that dept. Pretty sure it is a leak somewhere in the is itself. But who knows
Do you have [RELEASE] Hub Information Driver installed? While it won't tell you what is causing the issue, it does give a good overview of memory and database use.
Another thing I might suggest is to watch your database size. I recently set every device to only store 11 events and 11 states. (Don't use less than 11, it makes the database do constant cleanups, which can slow the hub.) I also set the length to store events to 14 days. I had stuff from a year ago in the database, and I was never going to use that data. Between those two things, it made my hub much snappier. It wasn't slow before, but it was noticeably faster after pruning all that cruft out of there.
And while we are at it, maybe try a backup and restore? Maybe something is corrupted, and that will clean it up.