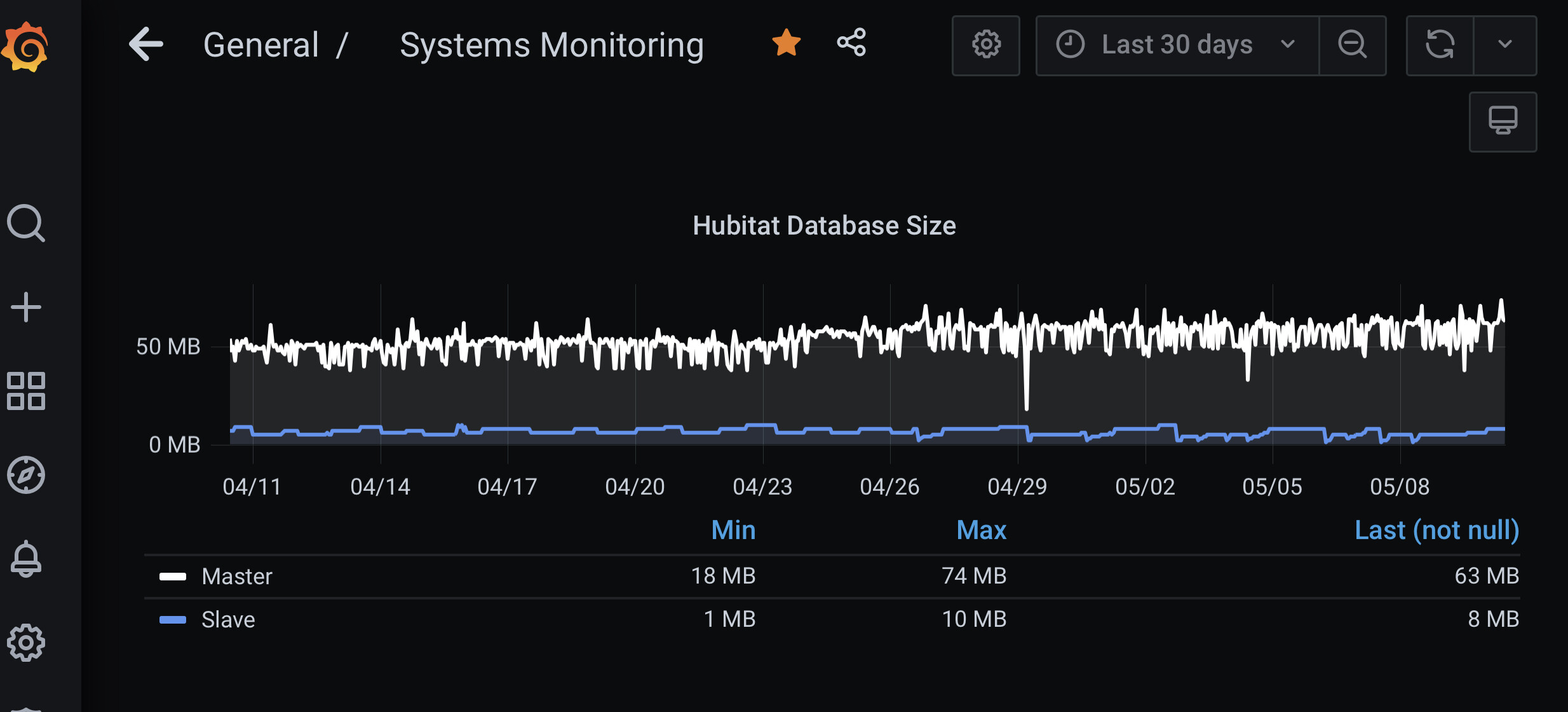
My event and state history have been '100' ever since that was an option several months ago. Looking into my logs, however, I see that many devices are ignoring this event history. (column marked 1 is events, 2 is states)
When I go to the device driver for one of those devices, such as 'Fireplace R' the event and state history are set to 100 (and, again, it has been set to 100 for several months)
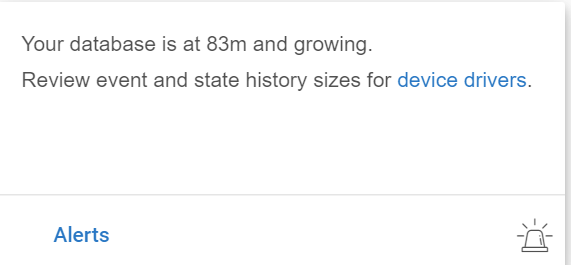
Just to make sure. What difference does it make to set event history and state history size to 10? I'm getting alert "your db is 93ms and growing" and size setting is 100 now. What db ms size I should be worried of...over 100ms... over 200ms... where should that db ms be by default?
I don't know about that... I have 65 devices on one hub and 95 on the other and have never seen it.
Guess it depends on your definition of "lots".
Really it probably more depends on how many "chatty" devices you have as well as multi-attribute devices. For instance a weather station device with 20-30 attributes that update frequently can take more database size than 30 individual single function devices.
In scenarios where there are a ton of attributes, or they are really chatty, reducing the retention settings definitely helps.
I'm confused what does that alert even means. Is it something that needs to take care of or just let it be. After couple of hours my db increased to 113ms.. and it's still growing..
What then?
Event History is the most useful, for me. I have a lot of acquired knowledge of how often I look at a device's Event log/history. Some devices get a visit quite often, other's probably never. Presence is one I visit a lot. BUT, I don't need to look back to 2019 If I can see only the most recent 10, I'm good. So I set the default pretty low... about 3 ( I have 7 hubs so I haven't taken the time to make this match on all.) Then I hit the devices I need more than 3 and set them to a more comfortable value.
State History is a bit more mysterious to me, but certain Drivers (weather and statistics) tend to have a dozen or more attributes, setting them low makes the multiplication work out better, DB size wise.
By attributes per device would that mean, for example, for Inovelli Red dimmers each of the many possible settings is a separate attribute whether it is used and set or not. That would make each Inovelli Red dimmer take up as much space in the database as, say, twenty Sonoff motion sensors without temperature.
Hum, I did all that (set to 5) and turned off all possible debug logging. Then rebooted hub and still I get alert at same level as before these changes.
That's the point, I reviewed them in detail and turned off logging (specifically Webcore) and other non-essential items, reduced the state size and history size, rebooted the hub. Yet, the baseline number (prior to reboot/alterations) remains the same and continues to grow.
Even if the action taken presented any change the baseline db stats should of changed. Yes, there were major differences (before/after) in the runtime stats for both apps and devices.
Is there a manual way to reset the database status which causes the alert as with all others, a refresh if you will?
I suppose from @Jani response there is an internal, non user accessible clean up routine that cycles every 24 hrs or some period.
Yes, I would think so from what Ive sampled in comments. However, the hub runs perfectly fine. Only some (slow) devices have any noticeable effects. All my automations (exclusively in Webcore) run perfectly. All my dashboards are fine, even the ones produced with Hubigraphs (resource hog).
Matter of fact, I had no idea what my database size was nor any reason for concern until after the upgrade that enabled the feature. It is good to have more visibility into the hub (stats), but sometimes ignorance is indeed bliss. LOL


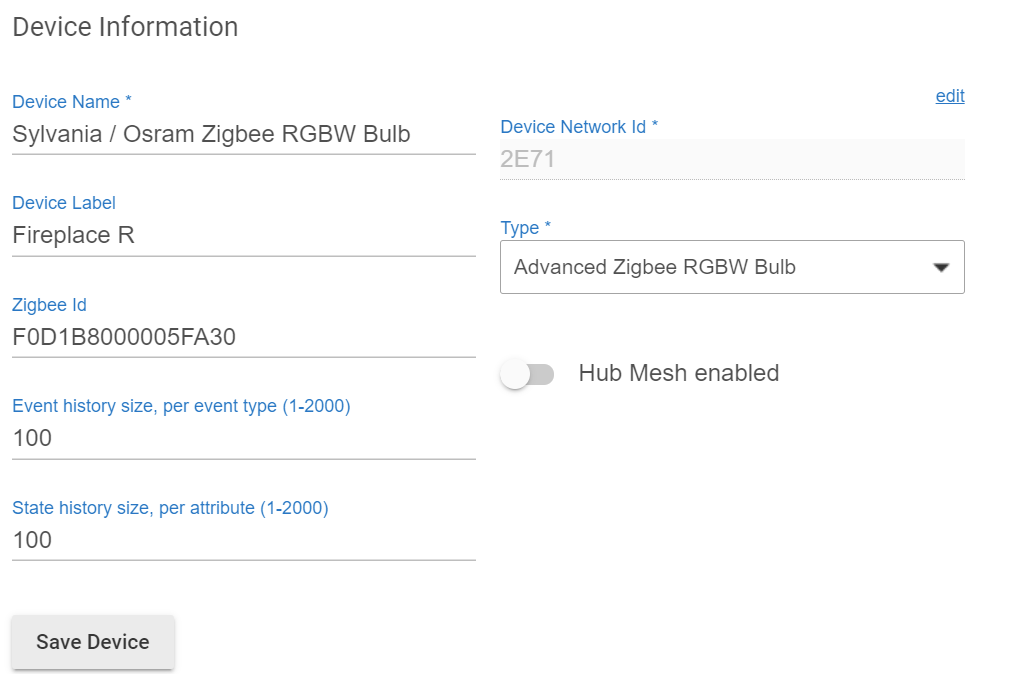
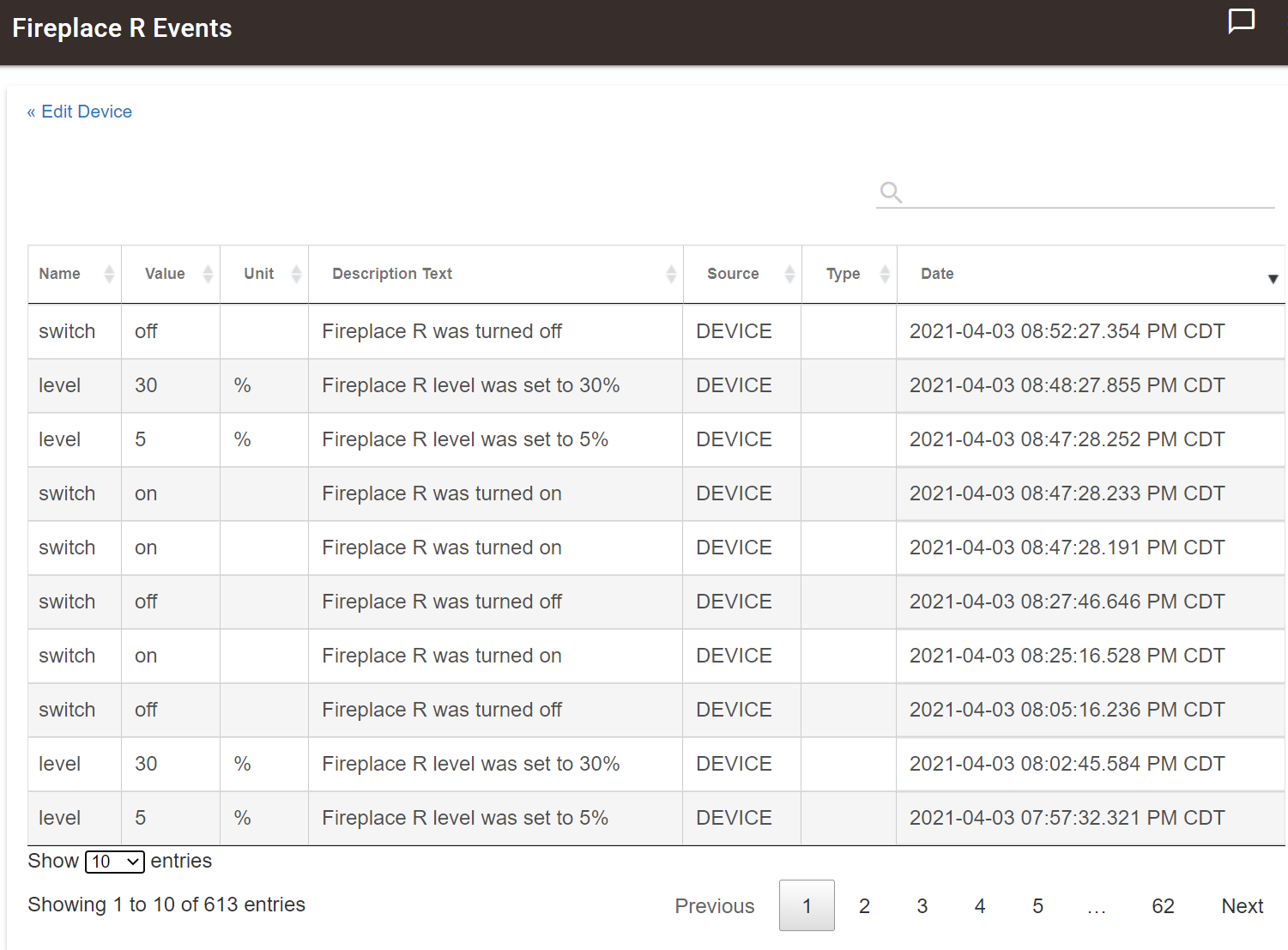

 If I can see only the most recent 10, I'm good. So I set the default pretty low... about 3 ( I have 7 hubs so I haven't taken the time to make this match on all.) Then I hit the devices I need more than 3 and set them to a more comfortable value.
If I can see only the most recent 10, I'm good. So I set the default pretty low... about 3 ( I have 7 hubs so I haven't taken the time to make this match on all.) Then I hit the devices I need more than 3 and set them to a more comfortable value.