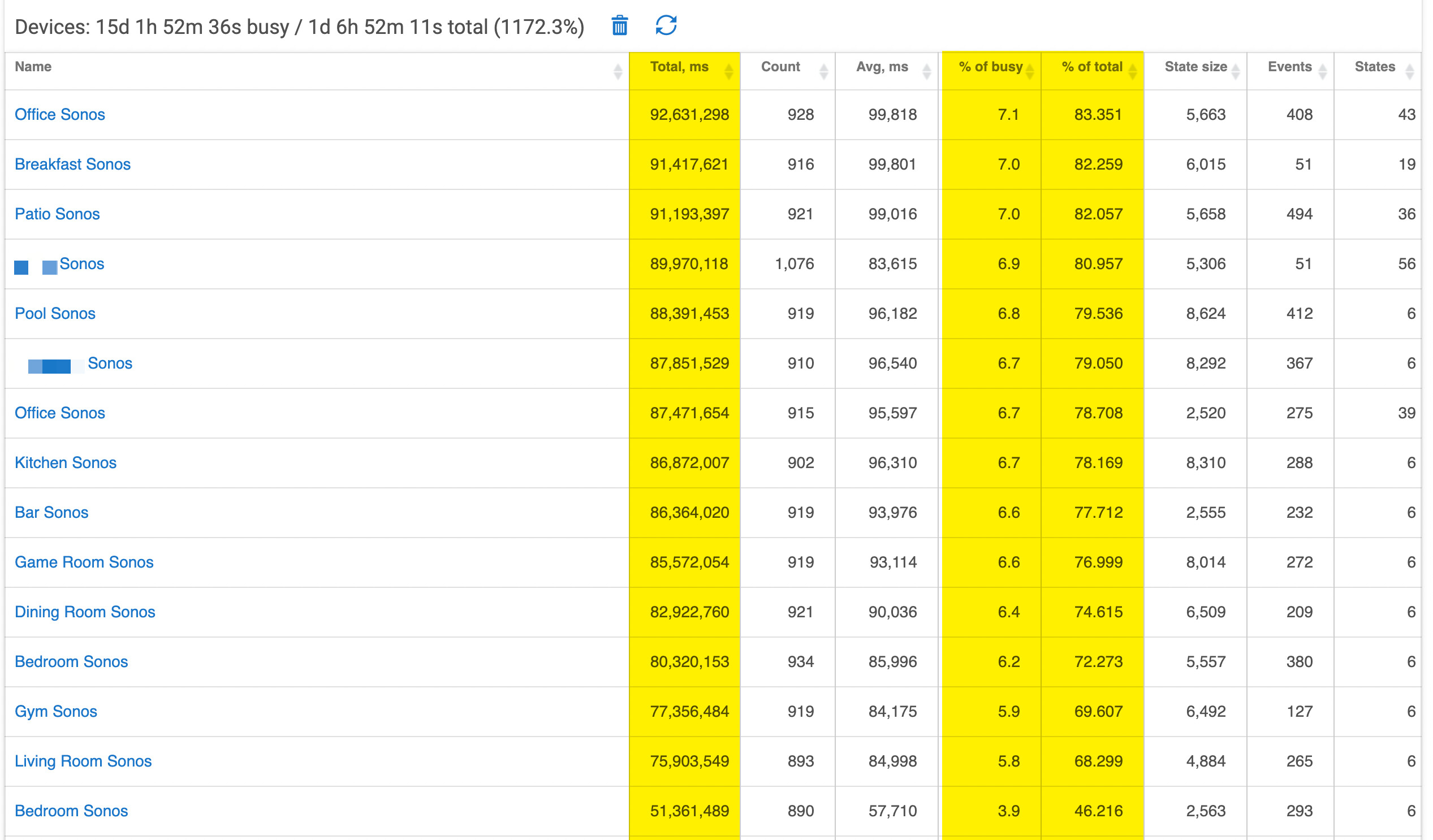
I took the plunge and upgraded my C-5 hub from a 2.2.4.xxx release to the latest 2.2.6.140 a few days ago. Ever since the upgrade I constantly am getting severe load alerts and the hub slows down to a halt.
Looking at both app and device logs, there are a few "offenders" which I have optimized and can certainly continue to do so.
However, the biggest offender seems to be the Sonos built-in integration which I can do nothing about.
Here is what the load looks like. Looking for any guidance on resolution or an ETA on a fix?
I should also say that I noticed that Rules (RM 4.0) that were placed in deliberate pause state were consuming a lot of resources for no reason as they are virtually inactive.
I removed all the paused rules for now to reduce load on the hub but find it odd that this should be the case.
I'm wondering if the stats may be a little off for some reason. Perhaps try and restart the hub and then assess the performance stats over a day or so? I'm not suggesting this as a fix to any underlying performance issue, just to have a clean slate to assess the stats from.
I had also noticed this previously, but only had one paused rule at the time, so didn't do anything about it. HE dev's can comment more on this, but I was wondering whether it was more a case of previous executions of the rules contributing to consumption of resources, more so than recent executions since they were paused? If that makes sense.
Something is wrong with the accumulation, you can’t accumulate 15+days of runtime in under 2 days. So, I’m left with the conclusion that either the accumulators didn’t reset or the DB is corrupted.
If you have any sonos devices on any dashboards, try removing them from the dashboards and see if it makes a difference.
Long time back there was an issue with "selecting all devices" to be used on dashboards, and the sonos (at that time) on the dashboard was aiding in my slow down.
Actually, just on @thebearmay 's point and my suggestion to restart the hub, you can reset the stats in that logs screen, perhaps you could try that first, rather than restarting the hub.
I reboot almost on a daily basis. The run time is correct and the 15 days metric accumulates from zero when the system reboots. I agree that metric doesn't make sense hence some bug is in play either in the load calculation or elsewhere. Nonetheless the effect is 5hr same. About 12-15 hours after each reboot the hub is almost unusable and the zigbee radio goes offline.
I'll try the dashboard suggestion. I don't use HE's built in dashboards other than playing with them initially before you nchose sharptools. I might as well delete them all and see if it makes any difference. Thanks for the suggestion it sounds like a good thing to try.
This may be unrelated but I had an issue with sonos returning an error causing lots of retries. I saw it in the log once I put on debug information. I deleted my sonos devices. And recreated them. It seemed to fix the problem and my hub had much less load for sonos afterwards.
I had mucked around with IP address assignments on my network and some other things and I was never sure if the root cause, but a delete and recreate in hubitat fixed the issue.
I went through a similar thought process when deciding what to do with my (then) existing C-4 hub and new C-7 hub, I chose to keep my wifi-based smart plugs along with Dashboards, Maker API and other resource intensive features on my C-4 and put my lighting on my new C-7.
Perhaps a similar separation would be beneficial...
If your paused rules have schedules in them, trigger at set times or run every 30 minutes etc, then those rules schedules will still run. They will not do anything but the schedules will run.
If you choose the stop option then all schedules etc will be cancelled and the rules will be dormant.
May be worth stopping instead of pausing.
(This is my understanding or the pause and stop options).
And the winner is... @waynespringer79. Getting rid of my (unused) dashboards did the trick. Hub is down to ~18% over the last 24 hours with all Sonos devices and all.
Thank you all for the very valuable suggestions.
In earnest I am pretty good at diagnosing issues but the dashboards angle was not even a possibility that crossed my mind.
So... I spoke way too soon. A little over a day after the HE dashboards were removed, the Sonos devices climbed their way to the top overloading the hub yet again. I am now attempting to remove the SharpTools dashboards I have (which are the ones that are actually occasionally used) to see if that resolves the issue.
So... What has changed in 2.2.6 both at the core and at the Sonos integration level that would cause millions and millions of events to generate for each device and bring the hub load to a screeching halt?
There is also something definitely wrong with the math ontop of the device and app utilization statistics. Seems like 1172.3% load is not feasible for any environment to actually report.
The last message that I saw claimed that the HE database had over 80 million events in it and I'd like to be able to purge them all together as I have no use for state or event history for more than a rolling last 10 or so.
Is there a method that allows to schedule purge of events from the database or
Is there a way a reset events performance counters (and actually a reset of device generated events) without rebooting the device?? Seems like we should have more control on things that overload the hub when it comes to how it is behaving behind the scene.
I'll move the performance question / issue to a new post as I think the problem is more generic than just Sonos even if Sonos seems to be the trigger in this case.
From memory there is an option that is displayed from the alert screen on the database size, allowing you to adjust the global settings for events and attribute state history. I think that takes effect next time a database cleanup occurs, which may be during the overnight backup process. In my experience it seemed to take a day or two for it to fully reduce, but that could have been something specific to my setup...
I think there is a hidden page where you can change these settings when there is not an alert on database size, I'll see what I can find...
Thanks. I did that but I'm not convinced it purged the 80million historical records vs. limit accumulation of future events. How often that the table prunes itself, how does one ever access all this history to begin with and are 80 million rows a reasonable accumulation for the actual size and performance of the hub altogether? At what point in time, the database or the hub get to a choking point or consume too much cpu attention at the infrastructure layer leaving less and less room for applications and devices above them to adequately perform?