Did you try a reboot before rolling back? These are similar errors to things going on with DNS caching discussed here.
I was able to capture the exact same error you are describing, but it really is the fact the IPv4 you are attempting to communicate with is in fact, not the same DNS server authorized and telling you the cert is invalid (which is true). A reboot will clear your DNS cache and make everything happy for a little bit again.
@gopher.ny any timinig on new code to solve the DNS cache problems??
I didn't. I suspected that a reboot would solve it, but I also suspected that the bug was introduced in .180, and I wanted to be on a platform version that doesn't require random reboots.
I know some folks have mentioned tricks in the forum, but if it isn't in the diagnostic tool, I wouldn't advise doing it. I have set a reboot every night until they fix it.
@gopher.ny With a bug this bad, you guys should really do a full rollback. Re-release .166 as .181 so that hubs can reinstall it; then, release a proper fix when you have one.
Has anyone other then the OP experienced this issue. Don't get me wrong I believe you in that this is a issue for you, but how wide spread is it. I just checked my grafana instance for log data and I haven't had a single instance of this error. I do use SSL allot even with my own integration, and not a single error.
These also seem to be related to external server certs not matching correctly. That isn't a cert in the Hubitat's control really.
So I am curious. What are your DNS values configured on the hub. What happens if you change them? does it make any difference. It seems like the speculation is that the DNS entries are cached and not being refreshed when they should.
I didn't do any special DNS configuration on my hub. It's assigned a static IP at the router. All the network configuration in the hub is left at the defaults.
Since that's a name resolution problem, it shouldn't matter what DNS configuration I have, as long as it's valid. It does make sense that incorrectly resolving a hostname would cause SSL to reject a certificate.
EDIT: Maybe changing the DNS configuration while it's in a bad state would cause it to dump its cache and solve the problem. I didn't try that, nor do I plan to: I just want it to work properly.
I have basically the same setup. My Orbi router is set to 8.8.8.8 and 8.8.4.4 and serves DNS on 10.0.0.1. This has worked perfectly for years (including avoiding all the cable DNS problems that Optimum has...).
What happened is the Hubitat team has changed the default DNS caching to the point where it doesn't respect the TTL from the DNS record. See my post here for more details on that, which is VERY bad.
DNS expects the client to honor the TTL since it’s handling things like geolocation, load balancing, and failover. Combine that with HTTPS, and anytime the IPv4 and DNS don't match, the TLS layer will reject the connection, just like we're seeing with all these various external services.
I REALLY HOPE they fix this soon. This would be a SEV1 in any major company I've worked for. It seems we're in limbo until then.
BTW: If you change the DNS in the Hub, it requires a reboot, which clears the DNS table anyway, so the workaround isn't really a solution.
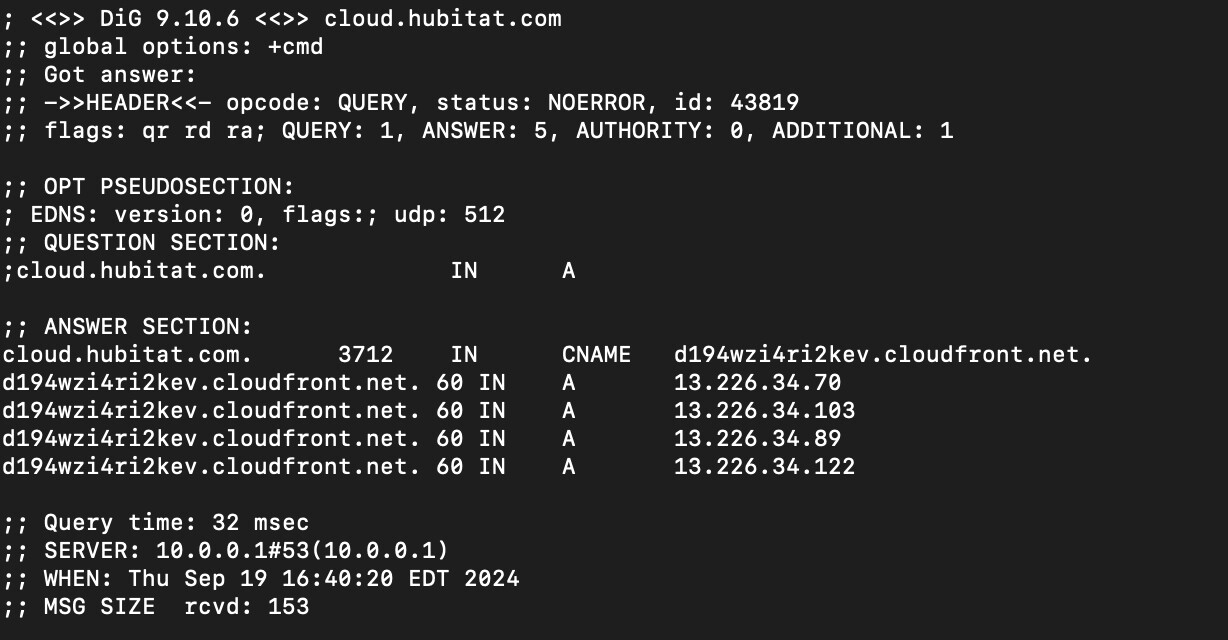
Hmm... seems like a possible suspect for the random cloud disconnects as well. Since the HE cloud url uses a CNAME as well with multiple A records tied to it. The TTL on cloud.hubitat.com is 10 seconds.
Remember the days when a normal DNS TTL was like 24 hours...?? If you changed something on DNS for a site you had to wait up to 24 hours before everyone would see the change. Was amazing when that suddenly became minutes.
It would be outbound connections that have the problem, since inbound would be listening to their own DNS. But yes, that CNAME has several IPv4s behind it, if one of those 18.238.25.X addresses is released and the Hubitat Hub had cached the DNS to the now missing IPv4, you would have the exact problem.
Yeah, not sure how the cloud connections works but it would suspect the hub is sending outbound messages to the cloud system to establish and maintain the link. So maybe if it cannot reach it anymore outbound the link closes and then any cloud links no longer work. This would make sense because often when it happens everything else on the hub, internal and outbound internet connections all stay working, its just the HE cloud system that stops working. Remote Admin, cloud dashboards, Alexa integration, etc...
It actually does. When you are getting a ssl rejection because a subject Alternate name doesn't match it is likely because the failed DNS lookup has routed you to a server that no longer has that hostname associated with the cert it is has loaded on it. SSL is very picky about the the FQDN used to get to the URL you are trying to access.
It does look like the problem is in Hibitat, but i don't understand why it isn't more wide spread. I did find occasions of it. In my setup it seems to be centered around @Bloodtick_Jones driver roborock driver, and i also see it with a weather driver. I dont see it though with other cloud based services. I wonder why i haven't.
My guess is that if the IP and DNS CNAME records aren't changing, then the SSL cert will be fine - This is likely just an issue for things in the cloud are behind a load balancer (NLB or ALB - Which is the "normal" way to do things in AWS, etc). - So if the cloud destination is static (IP, FQDN, and SSL aren't changing), then things should just fine.
Things with very short TTLs, and IP's jumping around behind a load balancer are definitely going to be impacted - So it depends a bit on what your talking to, on the cloud end of things - And depending on their cloud or AWS setup (lots of dynamic load shedding - Spinning up new EC2 instances based on load, getting a new VPC IP address, and a new CNAME added to Route53 - All done to lower AWS costs and be responsive to demand - That "dynamic nature" in the cloud would be problematic - Versus just some static EC2 server with with a public IP
Sounds like RoboRock is using load balancers (as they are designed to be used in AWS) - That's my understanding how this could be very intermittent and dependent on different backend cloud setups.
I get what you are saying and that all makes sense. But what I don't get is that i have a few integrations that i use that are cloud based. The only ones having issues are the the RoboRock integration from @Bloodtick_Jones and the OpenWeatherMap Driver.
The issues when occurred also all fixed themselves and as of right now is not occurring. I haven't done any reboots for it to recover.
I also use Ecobee suite that is cloud based and the Govee Integration that runs on Amazons AWS platform as well. Neither of those have had issues.
I guess it is possible neither of those use LB's to reduce/spread the work load, but I would be surprised if that was the case.
SmartThings integration, potential hubitat and SharpTool cloud disconnects, and any other service that relies on external cloud infrastructure may and at some point will encounter issues. It's inevitable that, at some point, a CDN or cloud hiccup will occur, and this forum will likely be filled with reports of services not functioning properly. In this case, Roborock seems to be the early indicator of such challenges. (Canary in the coal mine)
I believe we have their attention, but the lack of timely action is a bit discouraging.