So based on a few other threads I have started to look at how to use Ollama with Hubitat. The hopeful outcome will be a fully local voice assistant.
I have a working environment of Ollama with a few LLM's that I am working with. The goal was mostly to learn about them, just see how useful they can be and how they differ. I have experiemented with some LLM's with as few as 1 Billion parameters, up to a 67 Billion parameter model. In the other threads that are discussing Future Proof AI, or local voice assistants. I had stated that it looked like this shouldn't be to difficult to do so i wanted to give it a try and am starting this thread to produce the outcome of those testing.
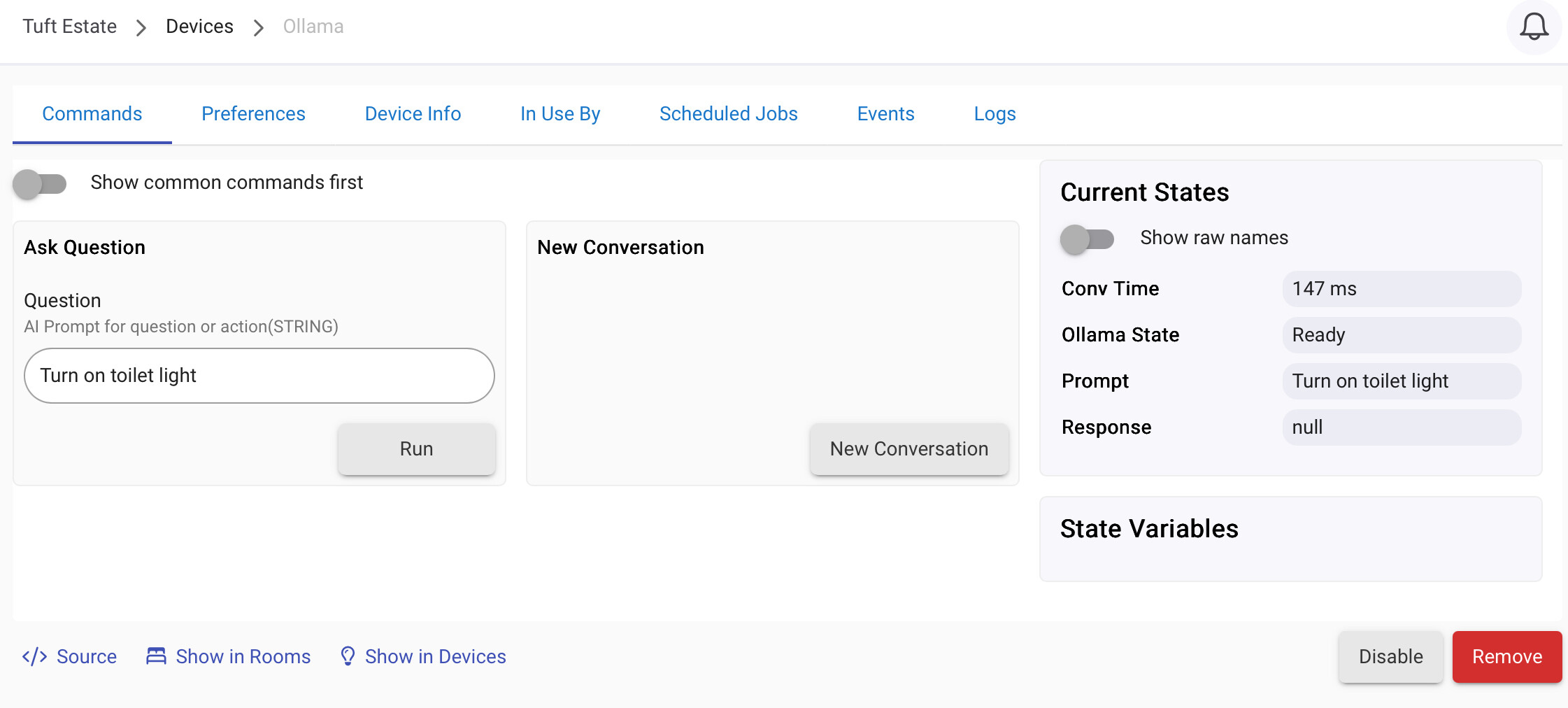
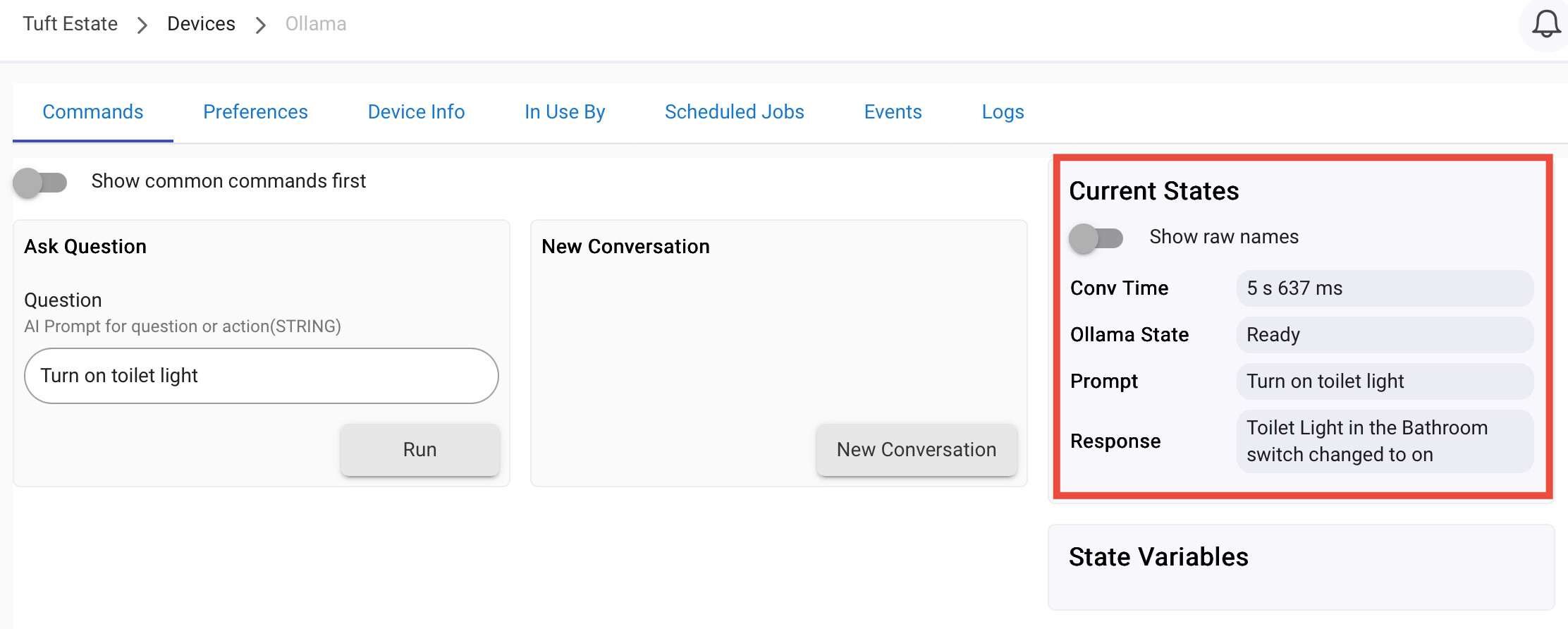
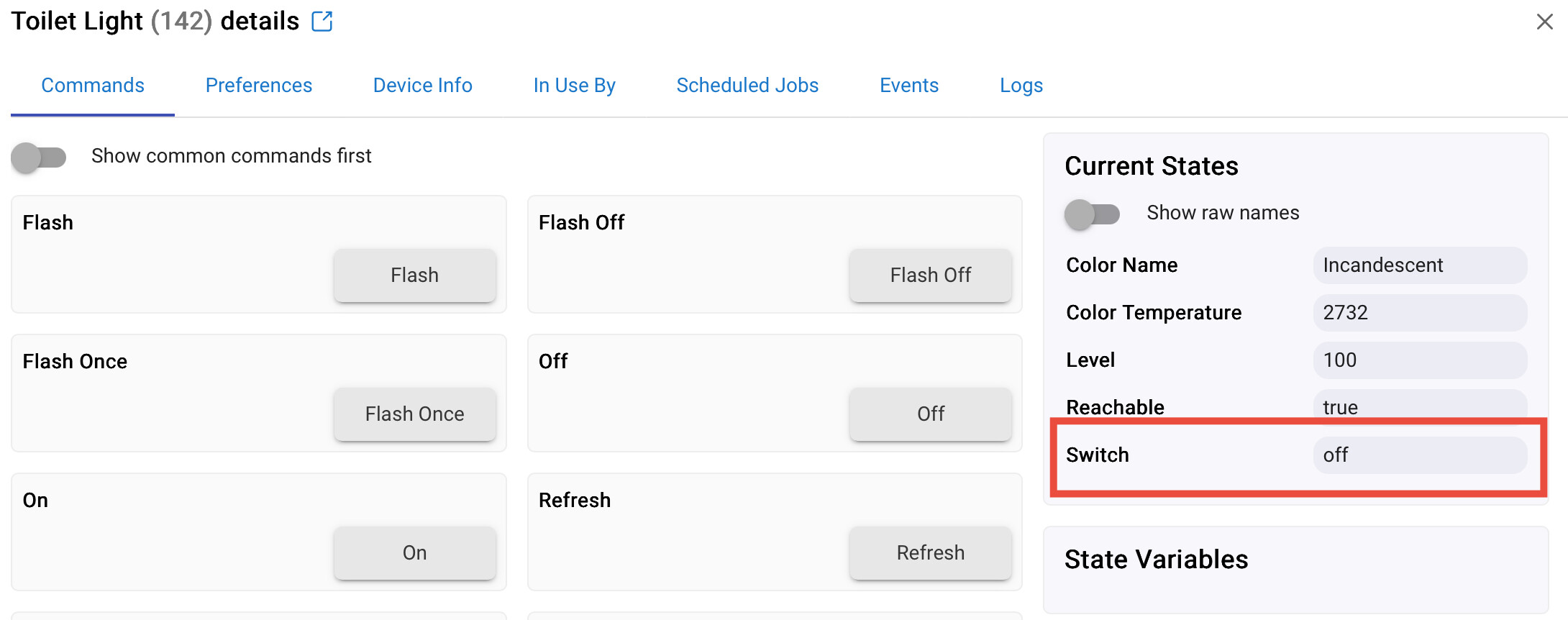
That said I have made some interesting progress all ready. I have created a Ollama Driver that i can use to have a conversation with Ollama. I have also added some functions to the calls so that now I get a response that includes the details Hubitat needs to act on. So that means i can use the device in Hubitat to have a chat with Ollama and say something like "Turn off the Lyra Lamp in the study" and hubitat gets a response that indicates something like "state" = off , device = Lyra Lamp, room = Study. This is pretty cools because i can now write the code to take that information and process it on any device.
One thing that I have found that i was wrong about was that i was hoping to use a fairly small LLM like llama3.2:latest with 1 or 3 Billion parameters that can easy run on small hardware. Atleast for now i have found i needed to jump up to a 8 Billion Parameter model call Qwen3:latest with some reasoning to improve reliability of the function identification. So far since making that change it has worked flawlessly. More processing is involved, but that larger model does make a huge difference. I expect this model will use my 8GB GPU, but anything larger will likely be a issue.
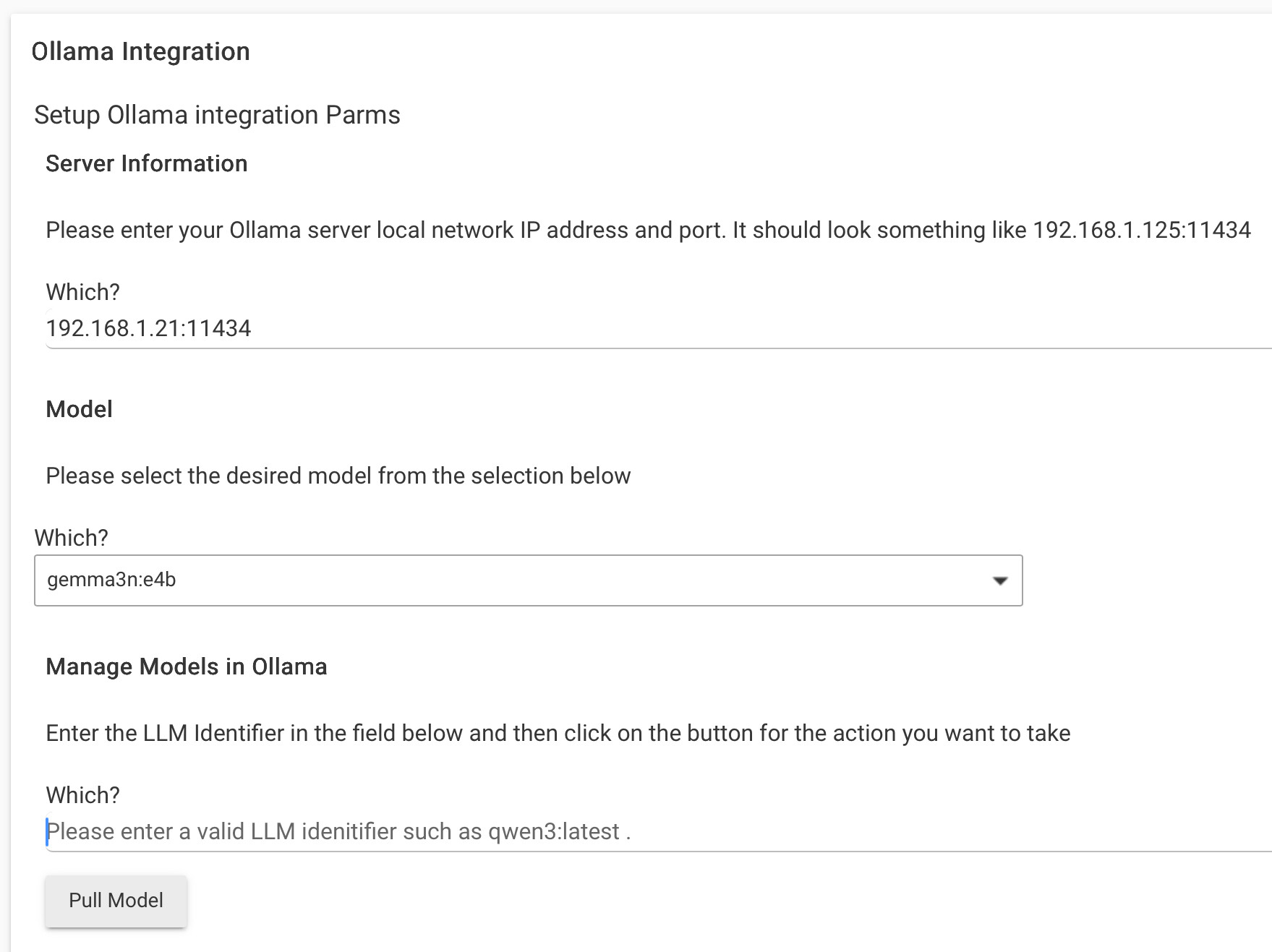
I neeed to work on a frontend app for the integration to manage config and to handle some of the additional logic that will take the returned data and actually act on it.
I can think of a few functions, but for more niche functions I may need help identifying them. I am really curious about everyone thoughts. Is this even something that we would want for Hubitat?