Installing Grafana
At the time of writing, the latest version of Grafana is v9.0.0, and the official installation instructions can be found here. https://grafana.com/docs/grafana/latest/setup-grafana/installation/
To install the latest OSS release:
sudo apt-get install -y apt-transport-https
sudo apt-get install -y software-properties-common wget
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
Add this repository for stable releases:
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
After you add the repository:
sudo apt-get update
sudo apt-get install grafana
Start the Grafana service:
START THE GRAFANA SERVER WITH SYSTEMD
To start the service and verify that the service has started:
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl status grafana-server
Configure the Grafana server to start at boot:
sudo systemctl enable grafana-server.service
We can verify Grafana is running by browsing to the web interface on port 3000, http://localhost:3000/:
Grafana: Log In Page
At this point, I recommend Logging into Grafana and changing the default admin password.
So far, so good. We now have InfluxDb and Grafana running, but before we can start constructing some charts and dashboards, we need some data.
Setting up a Data source
We need to setup a data source so Grafana knows how to get to our InfluxDB Database. When InfluxDB migrated from their version 1 to Version 2 they changed their query engine. For that reason we are going to setup two data sources. This will allow you to select the write connection for any dashboard you may get.
Data source v1
First you need to create a DBRP entry for the legacy connectivity to the database. This is done by using the Curl command on a computer. Open up a terminal or command prompt and submit the command as shown below for your OS. Fill in the fields based on the information collected earlier in the text file.
Windows syntax:
curl -H "Content-Type: application/json" ^
-H "Authorization: Token <YourAuthToken>" ^
"https://<url of server instance>/api/v2/dbrps" -d "{^
\"bucketID\": \"<bucket ID>\",^
\"database\": \"<database name to use for grafana>\",^
\"default\": true,^
\"orgID\": \"<Org ID>\",^
\"retention_policy\": \"<Just a retention name>\"^
}"
Linux/Unix/MacOS syntax:
curl --request POST https://<url for server instance>/api/v2/dbrps \
--header "Authorization: Token <YourAuthToken>" \
--header 'Content-type: application/json' \
--data '{
"bucketID": "<bucket ID>",
"database": "<database nam to use for grafana>",
"default": true,
"orgID": "<Org Id>",
"retention_policy": "<just a retention name>"
}'
Here is an example of what I used when setting up my test. I did it on a Linux VM so i used that example
curl --request POST https://us-central1-1.gcp.cloud2.influxdata.com/api/v2/dbrps \
--header "Authorization: Token SHwM4FOKC93akQV6sbBAGDib45RWZk6KgWM5zb_uy5yBWaUvcwLank7taeMxfJ8uoeQGOM_VEUQc6YYho-Y9GA==" \
--header 'Content-type: application/json' \
--data '{
"bucketID": "c7n67b803036ad8e",
"database": "Hubitat-v1",
"default": true,
"orgID": "de69d0957eg5c825",
"retention_policy": "7Days"
}'
Once you press enter you should get a return message with the same data.
As shown in the image below you will click on the sandwich icon in the upper left of the Grafana screen first. Then select connections in the menu that drops down below it. Once in the connection menu click on “Add New Connection” to be shown the screen below.
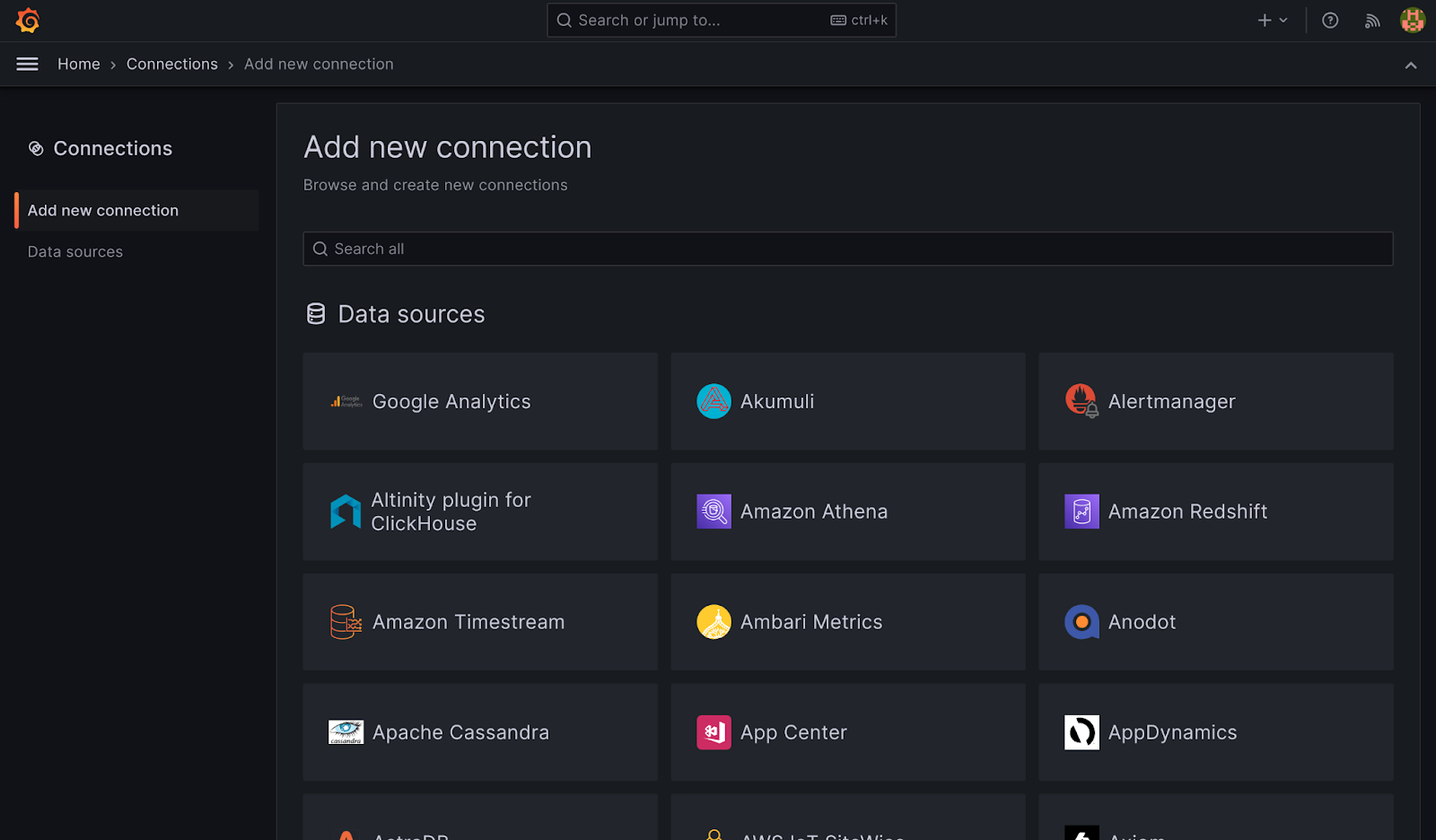
In the search bar type “Influx” The list should reduce to two options one of which is InfluxDB. Select InfluxDB to move to the setup screen for that database.
You should be presented with a new window that gives you some brief information about InfluxDB. Clock on the “Create a InfluxDB Datasource” button in the upper right. At this point the data source will be created, but it isn’t configured to work with anything. You can see the blank Configuration below.
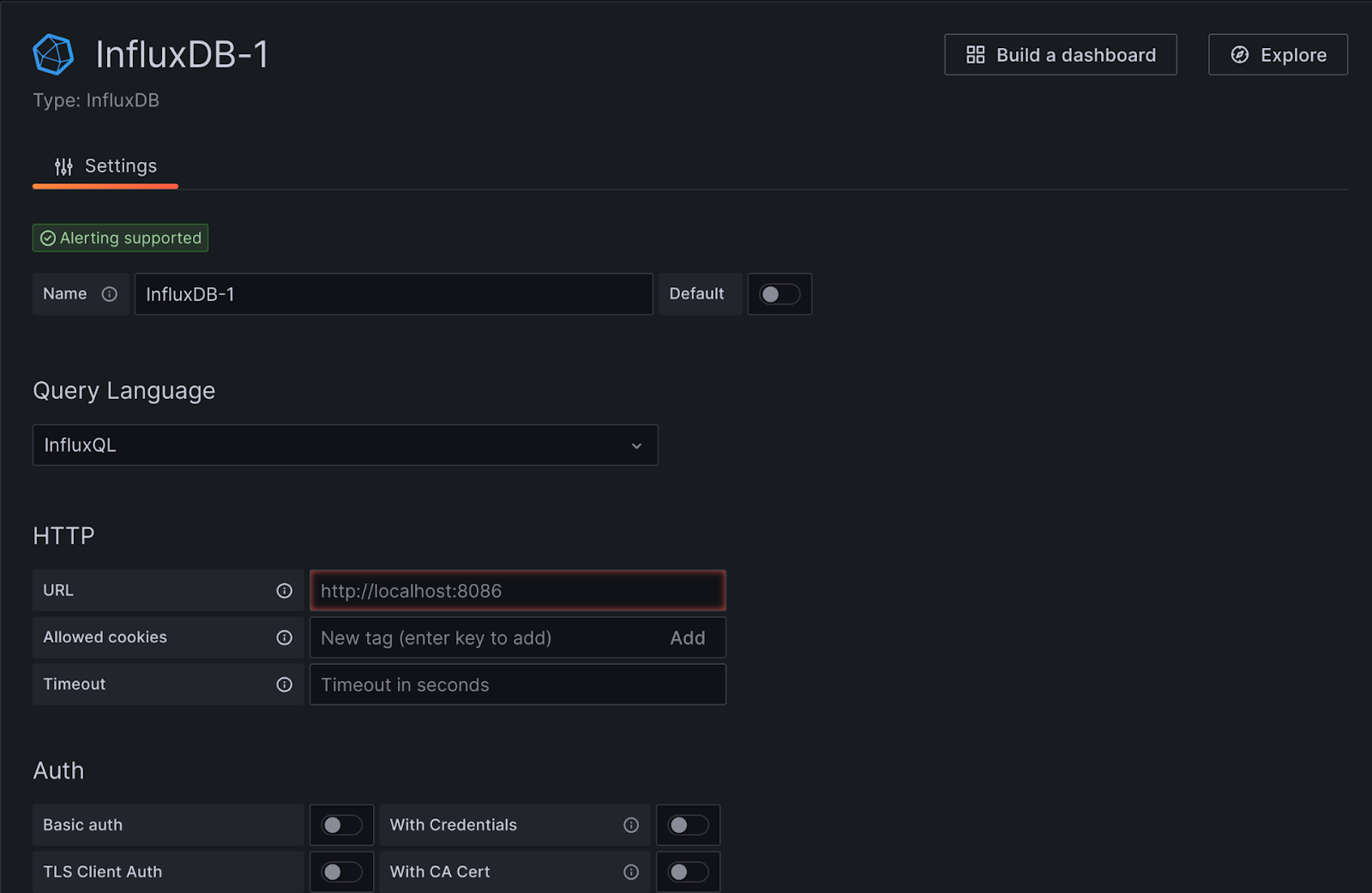
Now you will want to give this datasource a name. I would suggest ending it with v1 to indicate it is a legacy connection.
The URL will depend on if you are hosting your own instance of InfluxDB or using the cloud. If you are hosting your own it will be HTTP://”INfluxDB IP”:8086 (fill in your IP). In my case it is http://192.168.86.10:8086. If you are using the InfluxDB Cloud then you will want to enter the URL provided when you setup your INfluxDB account and we used for INfluxDB Logger.
Next we need to populate the Custom HTTP Headers value. This is what allows us to bridge the gap between v1 and V2 Query engines.
Under Custom HTTP Headers enter “Authorization” (exactly like that) for the Header and then “Token ” for the value. No additional spaces except for the one between the word Token and your actual token you obtained when setting up the database.
Example would be like this.
Token isCmd3f9r-GdSlMrdtX4wDjx9ER3hTIMUDW5cRvkv78RLNWAb8w5tVoSSBCEIbfrIFpXWFF4yfxy3UKmaBcUdw==
Once this connection is saved it will not be viewable as shown below, so keep that in mind.
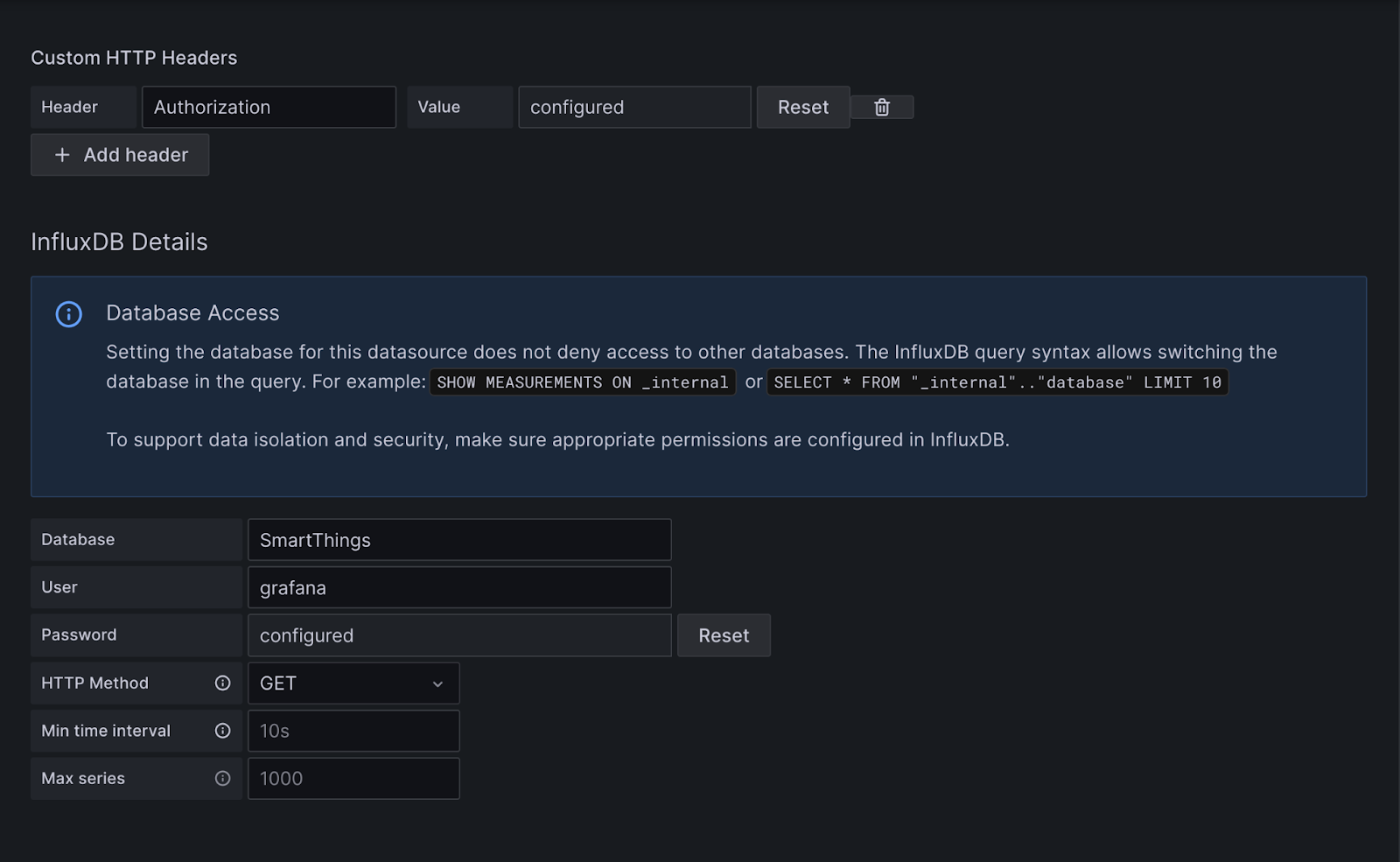
Now populate your Database value with the bucket you setup in your database and click on Save & Test at the bottom. You should get a success confirmation.
Data source v2
Setting up the V2 connection is very similar to the V1 except for two things.
For that reason follow the same steps as before and as shown in the image below you will click on the sandwich icon in the upper left of the Grafana screen first. Then select connections in the menu that drops down below it. Once in the connection menu click on “Add New Connection” to be shown the screen below.
In the search bar type “Influx” The list should reduce to two options one of which is InfluxDB. Select InfluxDB to move to the setup screen for that database.
You should be presented with a new window that gives you some brief information about InfluxDB. Clock on the “Create a InfluxDB Datasource” button in the upper right. At this point the data source will be created, but it isn’t configured to work with anything. You can see the blank Configuration below.
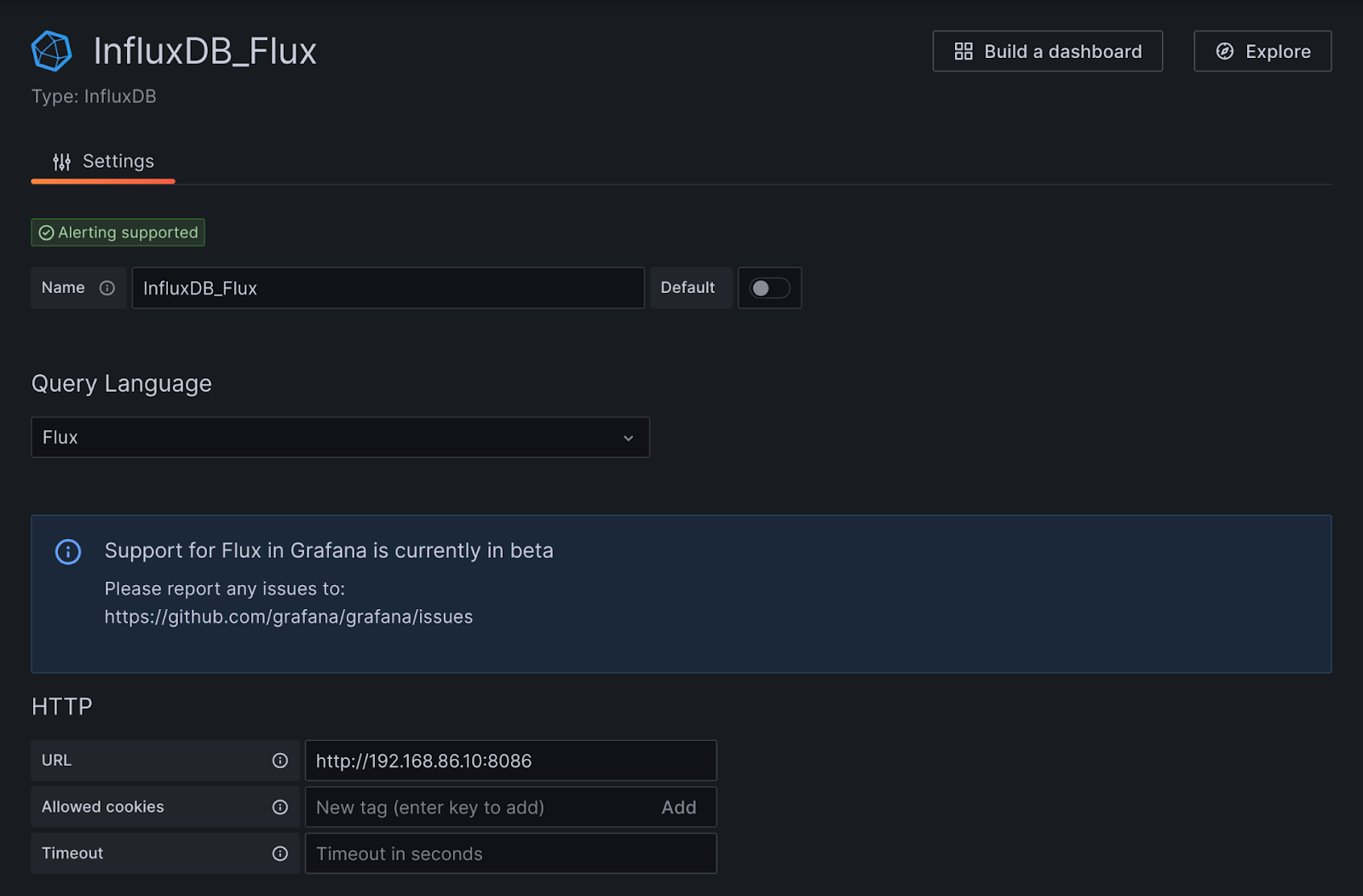
Now you will want to give this datasource a name. I would suggest ending it with v2 or Flux to indicate it is a new query method connection.
Yo will want to change the Query Language from InfluxQL to Flux as shown in the above graphic.
The URL will depend on if you are hosting your own instance of InfluxDB or using the cloud. If you are hosting your own it will be HTTP://”INfluxDB IP”:8086 (fill in your IP). In my case it is http://192.168.86.10:8086. If you are using the InfluxDB Cloud then you will want to enter the URL provided when you setup your INfluxDB account and we used for INfluxDB Logger.
The Token is the native way to communicate to InfluxDBv2 and once you select Flux as your query engine the options on the bottom will shift a little bit. You will not need to worry about custom header and instead simply populate the values in the lower section correctly.

So at this point all you need to do is fill in the Organization value(ORG), Database Bucket and token. These will relate to what you used previously in this setup. Once that is done you should click on the “Save & Test” button and get confirmation of a successful connection.

