I have a common callback for 4 temperature devices I subscribed to. The callback does nothing but log the info to a csv file so I can look at the history at some future time. It works great "but" every once in a while 2 or more temperature devices require the callback at the same time. I would prefer not to use a Occupied variable that is set at the beginning and cleared at the end to keep things straight. I would like to use a REAL semaphore. I imported "java.util.concurrent.Semaphore" and want to guard the callback from having more than one thread executing that code at the same time. So, I put a sem.acquire() at the beginning of the callback and sem.release() at the end. "sem" needs to be declared as "Semaphore sem = new Semaphore(1)". My first confusion is that for this to work I need to put this declaration of sem where it will have persistence and not be executed every time the callback is executed. It looks like atomicState, state, and Hub variables only support basic types... NOT Semaphore. Please help me understand how this could work.
Thanks
Have you already tried synchronized (as known from Java)?
BTW: Modern Groovy itself has also a better AST for this, but Hubitat Groovy is a little to old for this. ![]()
Would singleThreaded: true meet your needs instead? It's a lot easier if so.
Otherwise, for this, you'd need something like a static field variable rather than state. (Keep in mind these are shared among all instances of the code, unlike state.) And a hub variable is completely the wrong approach as I believed I explained in another topic you created.
Hi Jost, appreciate the quick response. I MUST be doing something wrong! It seems to be a very straight forward way of preventing race... but it isn't working for me. I will explain what I did and the results that makes me say this:
This callback has 5 subscribes for temperature sensors.
def MySemaphore(String Line) {
log.debug "BEFORE synchronized()"
synchronized(this) {
log.debug "*** ENTER MYSEMAPHORE ***"
pauseExecution(60*60*1000) // pause for an hour
log.debug "*** EXIT MYSEMAPHORE ***"
}
}
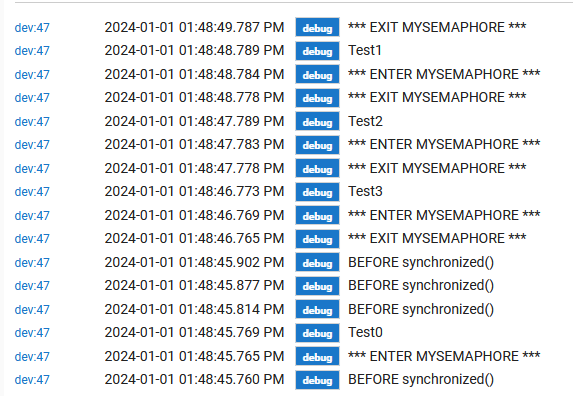
I then installed the App and allowed 15 minutes to allow all devices to execute the callback. I got the following log report:
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
I was expecting if the "synchronized(this) {}" was working correctly the following:
BEFORE synchronized()
BEFORE synchronized()
BEFORE synchronized()
BEFORE synchronized()
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
Of course the order of logging progresses from bottom to top.
Is my thinking incorrect or is it just not working?
Thanks Jost
Never worked for me either. I think because each entrance is a separate process and getting its i
Own semaphore. For my sendmail i eventually implemented each outgoing mail its own child process with a parent device ...in this.case the semaphore seemed to work in the parent device
The scope of this is the issue.
Try it like this:
import groovy.transform.Field
@Field String thisSync = ""
def trace()
{
[0,1,2,3].each { runInMillis(0, "MySemaphore", [overwrite: false, data: "Test${it}"]) }
}
def MySemaphore(String Line) {
log.debug "BEFORE synchronized()"
synchronized(thisSync) {
log.debug "*** ENTER MYSEMAPHORE ***"
log.debug Line
pauseExecution(1000) // pause for a second
log.debug "*** EXIT MYSEMAPHORE ***"
}
}
I added a log.debug Line to your MySemaphore method to demo this.
I think your correct and implied that in my initial post about the Semaphore needing persistence and not having a new one instantiated each execution. I think I confirmed that the "singleThreaded: true" scheme seems to work great... EXCEPT for the following:
My log when I ran the App and waited 15 minutes produced:
*** ENTER MYSEMAPHORE ***
BEFORE synchronized()
which is absolutely correct but I then got the following in the log:

I would imagine that the Hubitat OS is expecting a return from the thread of the callback sooner than 2 minutes. And of course I imposed a 60 minute delay. So it looks great and I have a solution. I would be nice to have persistence for objects other than the base types.
That may work, but it's a big hammer and may have other unintended consequences (for example, do you really want to lock out all other threads while this processes? may be fine, may not).
Check my post above yours if you'd like to try a more targeted approach.
I tried pauseExecution(121000), and the Hubitat framework still complains but at least doesn't totally give up:
![]()
Hi Tomw, I tried your recommendation and if works fine. The only thing I did different was I did not use the @Field and instead have "synchronized(this.MySemaphore)". Appreciate your help.
I just wanted to thank everyone for the responses that allowed me to successfully prevent a race condition in my App. The suggestion to use the following code:
def MySemaphore(String Line) {
log.debug "BEFORE synchronized()" synchronized(this) { log.debug "*** ENTER MYSEMAPHORE ***" // the next line just represents a VERY lengthy callback hog pauseExecution(60*60*1000) // pause for an hour log.debug "*** EXIT MYSEMAPHORE ***" }}
did not work but changing synchronized(this) to synchronized(this.MySemaphore) did work?? If you look above you will see a suggestion to use @Field and that also worked, but why all of these small changes made the difference I haven't figured out yet. If anyone has the reasoning for this I sure would appreciate it.
Just a final observation. I started this new topic wanting to know how I could impliment Semaphore(1) - acquire() - release(). I specifically needed to know where do I put the Semaphore(1) so it has the persistence needed for the functionality but would not get executed more than once. All the persistent tools (atomicState, state, HubVariable) only work for basic types and I needed persistence for Semaphore. I tried declaring "@Field static Semaphore sem = new Semaphore(1)" and then wrapped my protected code section with sem.acquire() and sem.release() and it WORKED. Again, Thanks for all the help.
if you look here i used mutexes extensively also with increment/decrement
Why not just use a concurrent map in the callback and a scheduled task every minute or three that writes the contents out to disk?
Solves the concurrency issue and reduces write time a bit most likely since you’re probably spending most of your time opening and closing the file.
Hi Daniel I think I like your thought about using concurrent map's. Let me sketch out what I think your recommending and if I am off the track please put me back onto it. I have one callback for 5 temperature devices (I can of course have separate callbacks but let me be stubborn for now). I believe you are saying use the concurrent map so that each device corresponds to a particular key and then put it's temperatures into that value field. And now that all 5 temperature value streams are thread protected and consistent and I can write the map info out periodically. If I portrayed your idea correctly I think that as I am writing the map info out I need something to prevent other threads (temperature devices) coming into the callback and writing to the map. I understand that concurrent map's will prevent that write if it is in use but I will be going from one key entry of the map to a another and the "in between" times of those accesses will allow a write. And when I am reading from the map it doesn't hold off any writes... correct? How far off the track am I?
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed.

