Oh interesting! So it looks like that the speed test is basically just
wget -O /dev/null http://speedtest.wdc01.softlayer.com/downloads/test.zip
and it does sometimes take that long to download the file, with or without HE. The server probably has a very limited number of connection slots so it is that slow to respond, but when it finally responds, the download itself goes quickly. Okay, that part of the mystery is solved and seems to be completely unrelated to the rest of the issue 
Only occasionally, as I have very few of those - but I do get a missed Z-Wave command here and there, like either porch or deck lights failing to turn off at sunrise. About 2 years ago I did the antenna mod, which solved almost all of my Z-Wave problems, and pretty much all the devices are connected directly to the hub with 1-3ms latencies, except for a couple of stubborn ones that keep change their routing twice a day despite being within 15ft and direct line-of-sight from the hub 
But the delays I'm seeing don't appear to be device-related, it's literally the time between seeing
dev:18 2024-02-13 06:51:11.585 info MBR Bathroom Motion Sensor is active
and
app:422 2024-02-13 06:51:12.906 info Action: On: MBR Bathroom Light
Almost like there's a stop-the-world garbage collector kicking in right in the middle of a rule execution.
I'm a fan of Z-Wave myself, and everything hardwired in my house is strictly Z-Wave. I use Zigbee primarily for sensors: I use battery backups for my repeaters, so if something goes wrong when the power is out, at least the mesh remains stable and sensors won't have to scramble looking for alternative routes, potentially dropping messages.
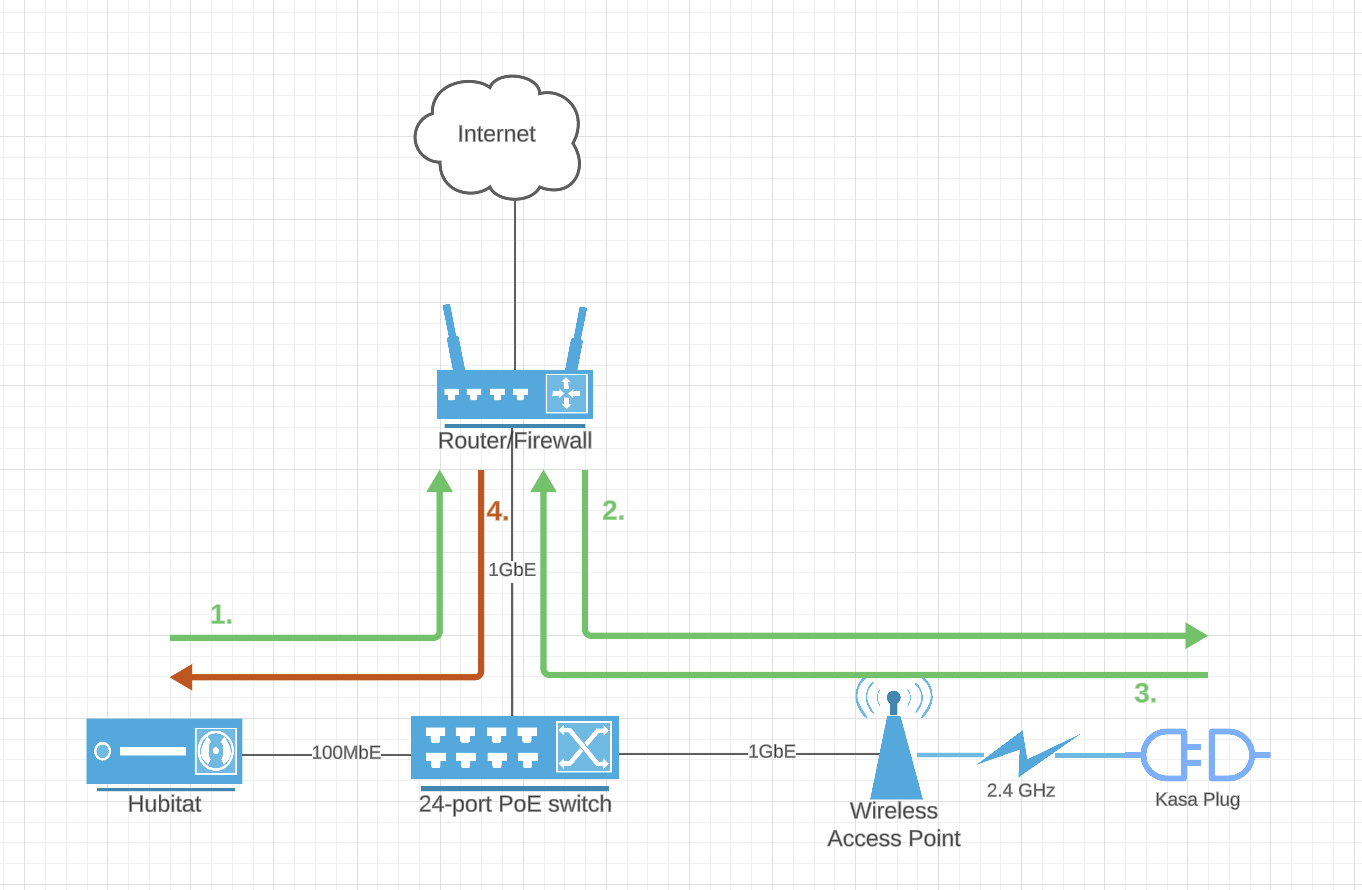
As for Kasa, it's even more interesting. I went way down the rabbit hole in the Kasa thread, but the TL;DR version is that responsiveness of the devices themselves is not the issue: it's the time it takes HE to process the response from the device. And since the same problem doesn't affect Home Assistant that I set up as an experiment (I even plugged it into the same network port where HE normally is), doesn't look like WiFi congestion is at play here.
Kasa commands are sent over UDP to port 9999 using hubitat.device.HubAction, with a callback function that is invoked when the response from the device is handed over to the driver code to process. Typically that round trip takes about 100-150ms.
I.e. command ("on") is sent -> device switches on immediately -> response is received by HE typically within 150ms, but can be anywhere between 1s and 10s, and I've seen it go as high as 23s.
It gets really bad twice an hour, when ZWaveNodeStatisticsJob runs.
I kind of expected that handling async responses for LAN protocols would have much lower priority than anything related to Z-Wave / Zigbee, I just didn't expect it to be that bad.
Now I'm debating whether to just move everything cloud and LAN to HA, or give C8 Pro a shot.