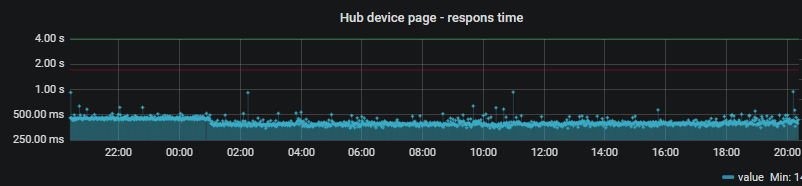
Not sure what's going on, but my Hubitat is quite slow via web interface (ESPECIALLY over iOS). Device listing takes a 3-5 seconds on a computer, and then a good 5-10 seconds when clicking on a specific device. But over iOS, device list takes 10 seconds, and clicking on a device can take 20-30 seconds.
I would like to say that the best tip is to try your way out by deactivating the 3rd party drivers and apps.
Check enable debug logging on these drivers and and analyze the log activities simultaneously. Unfortunately, this is very time consuming to troubleshoot because it can depend on so many different things.
A third option that I tried to activate was @btk 's wonderful good guide to measuring the performance of the HE gateway using Node Red. It is easier to quickly troubleshoot with this running. Disable and see the difference quickly.
The picture below shows the time it takes to load my http://hubitat.ip/device/list page. It measures the time every two minutes and the picture below shows the last 24 hours.
Unifi setup. Hub is hooked to a 16 port US-16-250W. Access point is a UAP-AC-HD. Router is a USG. Hubitat is on an IoT vlan, etc. It's gotten slower since I've had it, so it's some additional load I've put on it.
So network topology shouldn't be it. It SEEMS more like it's just hub load.
It could very well be some driver, to custom app. I have a guess that it's my tie into InitialState for logging device info.
Would really love to see some stats on the hub itself for CPU load, response time, etc.
Bruce has said before that CPU should not be an issue, and neither should memory.... Yet people still see slowdowns caused from SOMETHING (pretty much HAS to be CPU, memory, I/O subsystem, or drivers) - we just have no way of knowing what other than hunt and peck through the logs and pray.
So yes, I kinda wonder if it's IO. I had an interesting case last night of trying to load a device (Xiaomi contact sensor) so I could delete and re-add on my phone. And during the 30 or so seconds it took to load, I told Alexa to turn on a light. Alexa did it (turned on the light) but then timed out saying the light wasn't responding. So clearly Hubitat was so busy doing other stuff that it never fully responded to Alexa to say it had turned on the light. =/
Could be coincidence, but that's really what brought me to the point of posting about this since it's actually impacting more than just usability. =(
I get this more often than not and I don't know if it's related to the slow hub issue or not. Typically, it happens to me when I issue commands to non-native driver devices like my Sonoffs, but I've also seen it when turning on some of my Sengleds as well. The command does go through, but the response gets delayed back.
I to am experiencing huge slowdowns and delays in responses up to 1-2 mins. IF I reboot the hub the issue goes away for a day or so and then it slowly comes back. I suspect them might be a memory leak or something.
Probably. But good luck figuring out which user app/driver it is... As it is now all you can do is start turning things off and seeing if it makes a difference... Rinse and repeat.
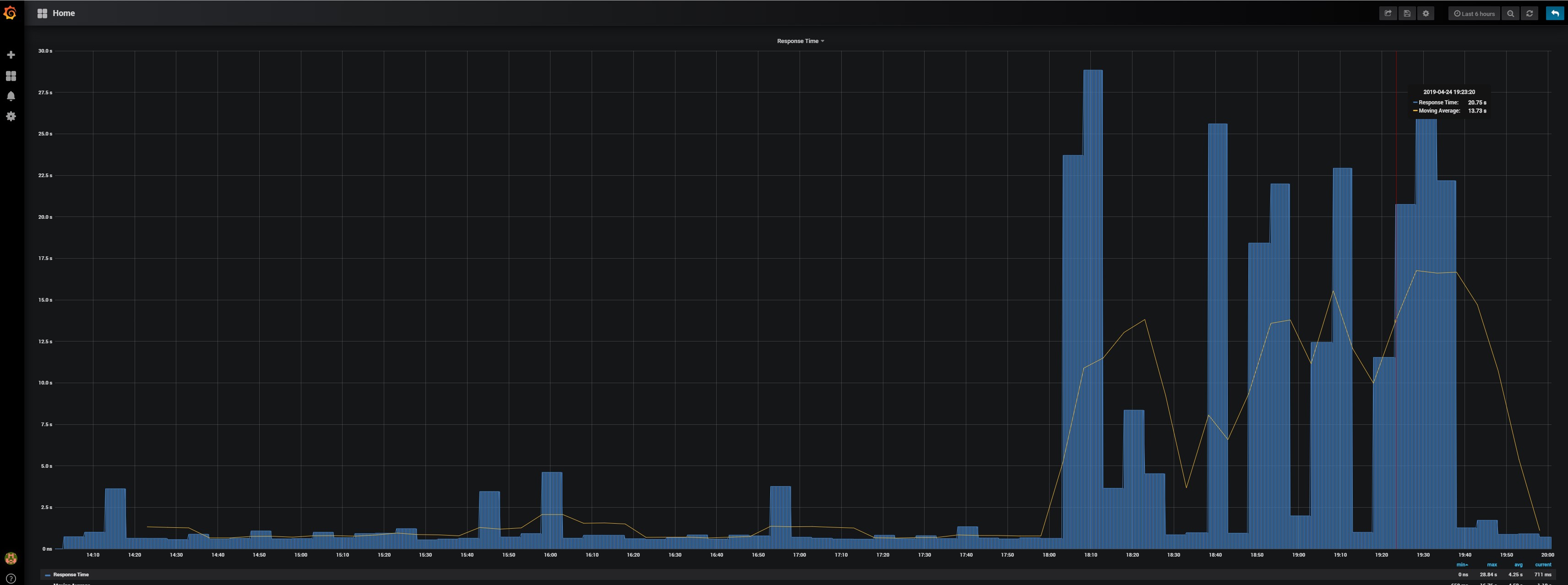
I experience it right now. See the graph where the charging times multiply from 1/2 sec to 3-4 sec on loadtime. Notice Google assistant having slowdown's to. Maybe it's becouse of that. I have some really heavy rules where things are activated by means of commands through it. Will try to debug it.
Any apps / device drivers that do frequent polling?
I was using the ported ST App Device Monitor until I realized it seemed to be related to the same symptom of a gradual slowdown of my hub which would only be resolved with a reboot.
Reliable Locks is the only thing that does a lot of frequent polling. I have a couple devices that do every minute polling, but I wouldn't think that would be an issue unless as I mentioned, HE is being hung up waiting.
All of sudden automations were not firing and I tried to login to the hub and received a 500 error. After checking the logs I see the following:
java.sql.SQLException: com.mchange.v2.c3p0.ComboPooledDataSource[ identityToken -> z8kflta2hztfb41scwikr|7188af83, dataSourceName -> z8kflta2hztfb41scwikr|7188af83 ] has been closed() -- you can no longer use it. (parse)
[dev:1445](http://10.10.20.10/logs/past#dev1445)2019-04-24 07:33:23.577 pm [error](http://10.10.20.10/device/edit/1445)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:2401](http://10.10.20.10/logs/past#dev2401)2019-04-24 07:33:23.306 pm [error](http://10.10.20.10/device/edit/2401)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:1985](http://10.10.20.10/logs/past#dev1985)2019-04-24 07:33:23.318 pm [error](http://10.10.20.10/device/edit/1985)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:2401](http://10.10.20.10/logs/past#dev2401)2019-04-24 07:33:23.314 pm [error](http://10.10.20.10/device/edit/2401)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:1020](http://10.10.20.10/logs/past#dev1020)2019-04-24 07:32:06.032 pm [error](http://10.10.20.10/device/edit/1020)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. on line 555 (parse)
[dev:1020](http://10.10.20.10/logs/past#dev1020)2019-04-24 07:31:34.690 pm [error](http://10.10.20.10/device/edit/1020)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. on line 710 (parse)
[dev:1020](http://10.10.20.10/logs/past#dev1020)2019-04-24 07:30:01.903 pm [error](http://10.10.20.10/device/edit/1020)java.sql.SQLException: Connections could not be acquired from the underlying database! (parse)
[app:1153](http://10.10.20.10/logs/past#app1153)2019-04-24 07:30:01.200 pm [warn](http://10.10.20.10/installedapp/configure/1153)unknownError: java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down.
[dev:1020](http://10.10.20.10/logs/past#dev1020)2019-04-24 07:22:19.735 pm [error](http://10.10.20.10/device/edit/1020)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. on line 706 (parse)
[dev:1283](http://10.10.20.10/logs/past#dev1283)2019-04-24 07:21:48.674 pm [error](http://10.10.20.10/device/edit/1283)java.sql.SQLException: Connections could not be acquired from the underlying database! (parse)
[dev:1283](http://10.10.20.10/logs/past#dev1283)2019-04-24 07:21:48.424 pm [error](http://10.10.20.10/device/edit/1283)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:1020](http://10.10.20.10/logs/past#dev1020)2019-04-24 07:21:48.397 pm [error](http://10.10.20.10/device/edit/1020)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. on line 710 (parse)
[dev:1449](http://10.10.20.10/logs/past#dev1449)2019-04-24 07:16:09.139 pm [error](http://10.10.20.10/device/edit/1449)java.sql.SQLException: Connections could not be acquired from the underlying database! (parse)
[dev:1537](http://10.10.20.10/logs/past#dev1537)2019-04-24 07:16:09.001 pm [error](http://10.10.20.10/device/edit/1537)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:1985](http://10.10.20.10/logs/past#dev1985)2019-04-24 07:16:08.361 pm [error](http://10.10.20.10/device/edit/1985)java.sql.SQLException: An SQLException was provoked by the following failure: com.mchange.v2.resourcepool.ResourcePoolException: A ResourcePool cannot acquire a new resource -- the factory or source appears to be down. (parse)
[dev:1538](http://10.10.20.10/logs/past#dev1538)2019-04-24 07:16:08.333 pm [error](http://10.10.20.10/device/edit/1538)org.quartz.JobPersistenceException: Failed to obtain DB connection from data source 'myDS': java.sql.SQLException: Connections could not be acquired from the underlying database! (parse)
I do not see a particular device listed either. After rebooting the hub everything seems to be fine.