If a hub is slowing down, it schedules a re boot.
The system, on a reboot, checks all settings and levels and sets them according to current system state. ( TOD, temp, motion active, presence...)
The recient updates to HE have so reduced the necessity of rebooting that it can handle it on its own. Largely by catching the CPU heavy load before it becomes noticable, and scheduling a "reset".
any way you can elaborate on these a bit? the screen shots are cut off. i'm getting the severe hub load messages frequently and looking for a way to automate the handling.
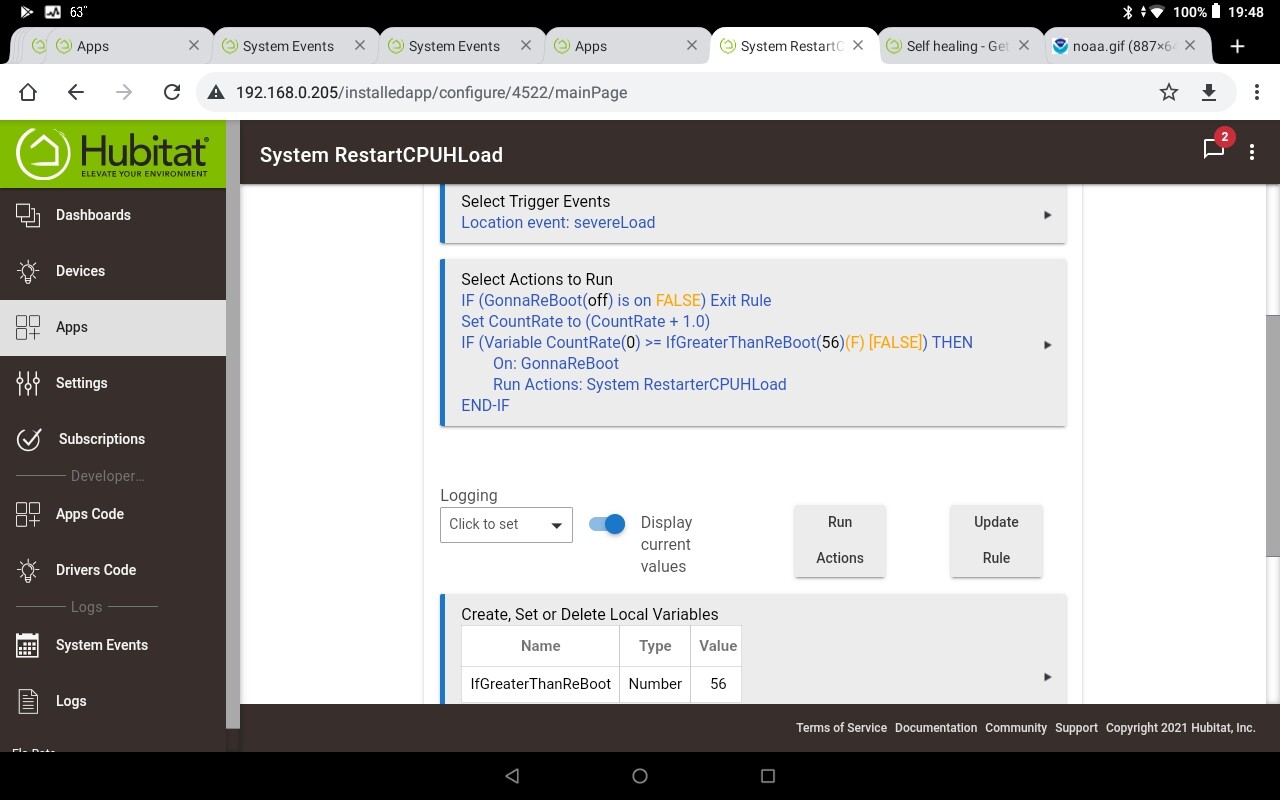
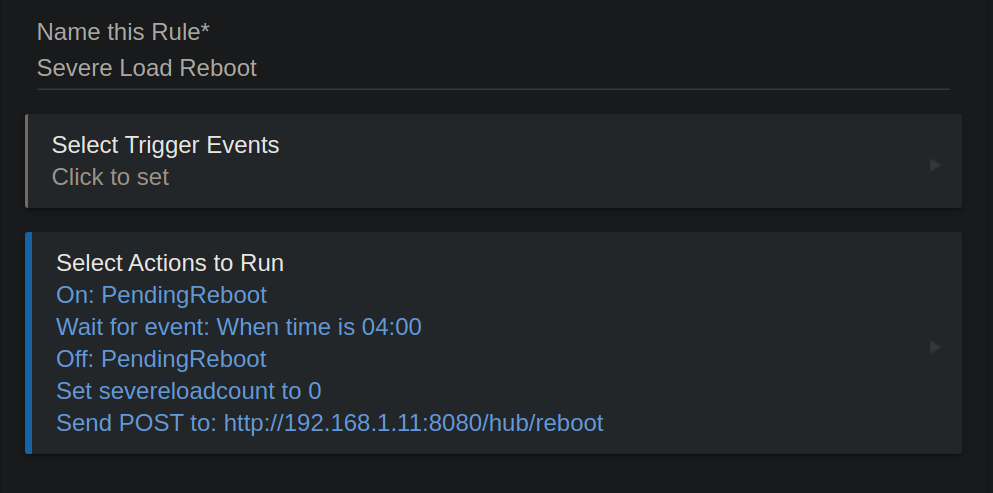
"GonnaReboot" is a virtual switch.
"IfGreaterThanReBoot" is self explanatory local variable. (Number)
"CountRate" is a global variable largely used to show on a dashboard if a hub is heading down the reboot path. It could just as well be a local variable if no "show" is required.
CountRate is referring to the hub "Flo-Rate"
Each hub has a different global variable: CountRida is for the hub "Flo-Rida" etc...
First rule increments global variable on the trigger of "severeLoad".
When global variable is great enough to justify a reboot, you pick the threshold, then the virtual switch is turned on.
Once virtual switch is on, run actions of second rule, basically a wait till appropriate time to reboot.
When the first rule runs again on next trigger, exit rule, the reboot is already scheduled.
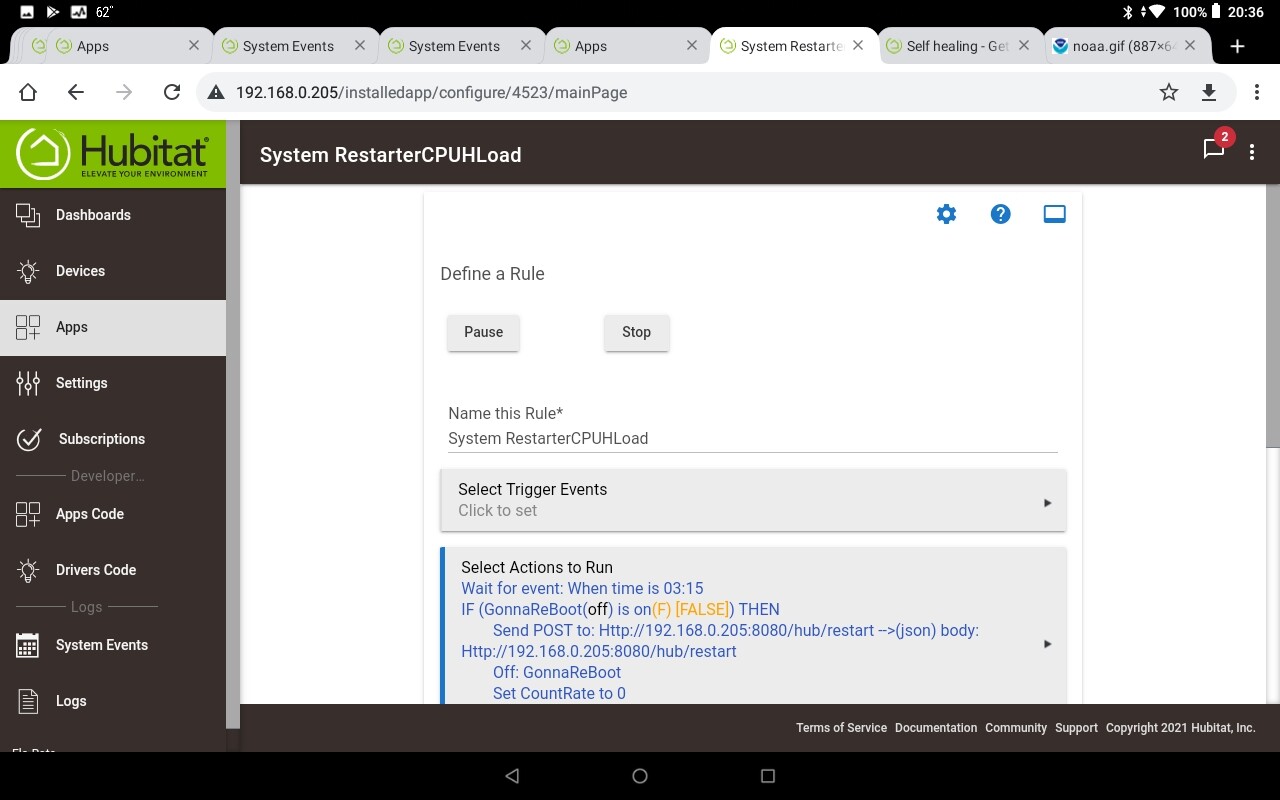
The second screenshot had an "endif" cut off.
There are no local variables in the second rule.
There are several ways that this rule set can be done, this is just the way I worked out, that works for me.
Most of my rules are able to be called from other rules.
Hope this helps, glad to attempt to explain my spaghetti logic.
Post yours when you are done, I am interested in other methods.
Great idea.
I've taken it and adjusted it to my style.
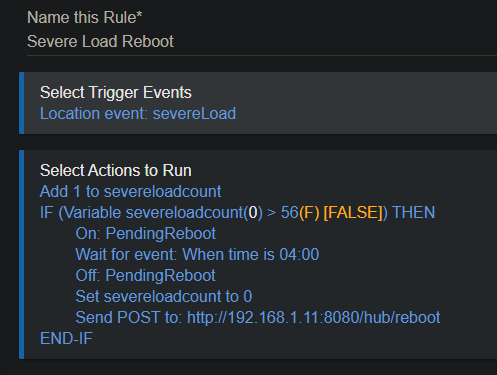
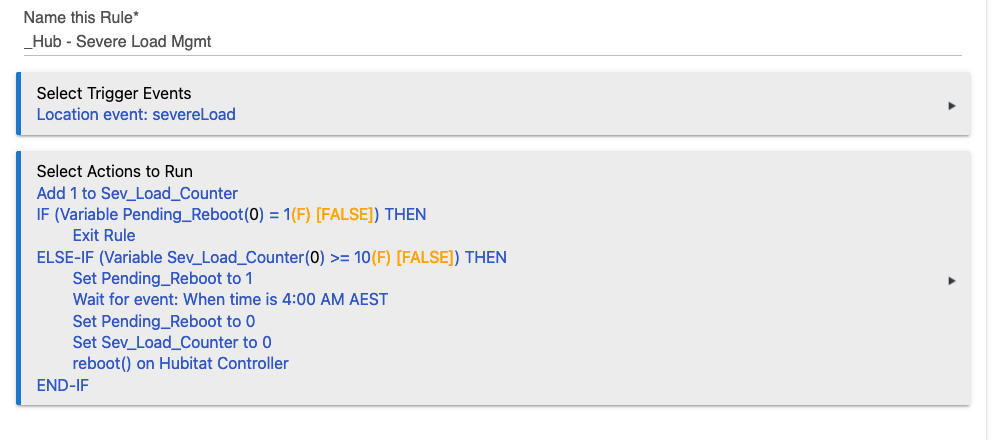
I simplified it down into one rule.
I removed the "IfGreaterThanReBoot" variable and just made that a condition in the rule.
I realized I don't really need the virtual switch since all the checking is done in one rule with the variable. I left it in in case it might be useful for a dashboard or another rule.
The URL for the post command is different. Everything I've read here seems to indicate that the URL is "/reboot", I tested that from the command line and it worked, maybe either is correct.
I also made the POST the last thing in the rule. I was concerned that the hub would reboot before it could reset the switch and variable. Just makes me feel better.
I am curious where you came up with 56 as the number to use? I haven't had any issues with slowdowns ( just doing this for fun), so I just copied that from your rule.
What do you think? It seems to make sense to me, but many times I think that and realize I am missing something obvious.
Hi @woodsy and @kyroha I like the look and idea of this.
I did have a spate of 'severe loads' but narrowed it down to 2 rules conflicting and everything has been ok since.
I will probably put in a notification if the hub is going to reboot.
I like the idea though and will have to copy this.
Thanks for posting.
Nice!
Simple and direct.
This rule evolved quickly, #56 was the shortest time frame before it would run, as I framed up the idea.
Of the 2 hubs that use this routine, at 5 day intervals so far, they start throwing the severeLoad event.and do not stop when the severeLoad occurs.
I should trim the 56 to a smaller number.
There are seemingly random sL events on 4 hubs, letting them run till a larger number have accumulated is best.
Freshly rebooted hub will trigger one sL event, so I like a little buffer.
The switch/variables allows other hubs to see it coming, next step is to do something with that information on other hubs.
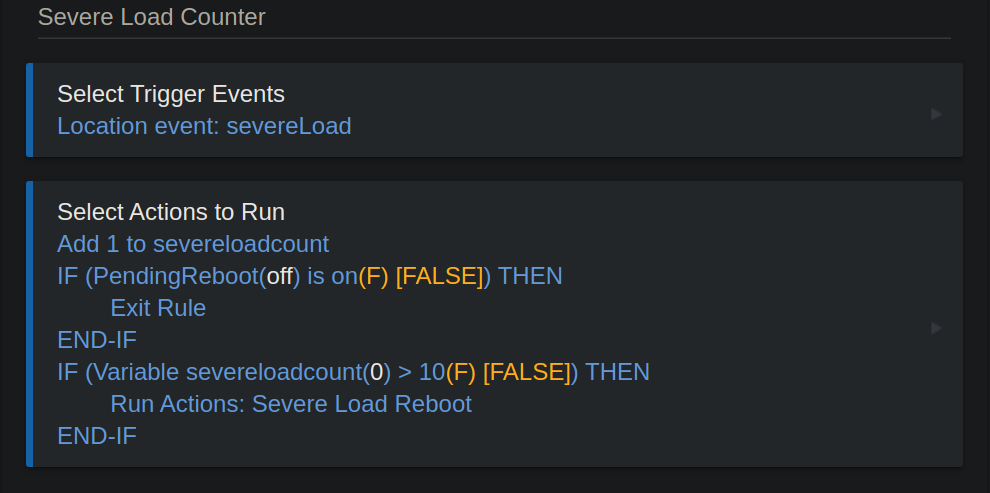
I would add to yours, that if pending reboot has triggered, exit rule as first line.
Hub is under stress, shorten the rule!
I've come up with this. My thinking is reboot at 3:30 if there is a minor issue. 10 instances of severe load through the day.
Reboot immediately if there is a major issue. 30 instances of severe load through the day.
I've then added a reboot count variable so that it doesn't go 'cyclic' if there is a major issue going on.
I would appreciate you thoughts/comments on this idea.
You've certainly sparked my very old grey cells.
Good thoughts, I get spurious sL events. 1 or 2. Maybe 6 in a row.
Example would be, I came home, motion and lighting and HVAC and fans and... Are all hitting at the same time, mode change and it's adjustments at the same time.
I am hoping to just keep it running till out of hours, then reboot.
Each hub runs it's "system normal" set of rules on any hub reboot.
Resets any settings to the default, time, temp, occupancy etc. dependant.
Tends to be noisy, many announcements "Flo-River is going normal", Mode is now XX. Etc.
These normal events are orchestrated by one hub. (and set to "quiet" after hours)
Not a pleasant thing to happen without control over timing.
This is just what works for me on my system.
Not much interaction, other than the occasional " I am hot, turn that fan on high"
Now it's stuck on high untill told otherwise!
Usually corrected by laying down and realizing that the lights are set manually, the fan is not on auto, corrected by calling out "Alexa, set system normal" and rolling over and going to sleep.
Long winded way of saying... It works so well on auto, I don't often have to change anything!
I thought about this. But my understanding is that when I rule triggers it clears any waits that are pending on that rule. Meaning that when the rule runs the second time it would trigger the rule and clear the wait, then exit the rule before setting the wait again. because the virtual switch is on. Making the reboot never happen. I could be wrong about this.
So If I am understanding correctly how RM works it seems it would be better to use two rules like you did.
Nice, seems very workable. For display purposes, will continue to increment severeloadcount. I looked at that yesterday in my rule as a better display indicator.
Do I have to interviene sooner. So far the hubs responds time has been tolerable till reboot time.
Nice work Chaps - if you have "Hubitat Hub Controller" installed (via HPM) you can simplify this even further down to a single Rule. Rather than make a Virtual switch, you can use a 2nd Global Variable.
EDIT: It's prolly a good idea to set the Load Counter variable back to Zero before the reboot as iirc global variables don't lose their last value during a reboot.
I've been having lock up issues (even when rolled back to 2.2.4), so I'm planning to try this out. I'm a beginer at RM, so may take a few tries. Thanks for the details on this.