Not sure if this adds any value. After rebooting the HE hub, I can fetch various sections within the Life360 hub app without error. After a brief time, I'll get.
TOO_FREQUENT:please wait 5 secs between calls! last:4ms
After that, just 403s
Not sure if this adds any value. After rebooting the HE hub, I can fetch various sections within the Life360 hub app without error. After a brief time, I'll get.
TOO_FREQUENT:please wait 5 secs between calls! last:4ms
After that, just 403s
I didn't think to try & check that. I would think if it was an ecryption thing it would cause something different but it's worth checking. I'll see if I can figure it out. With CURL I can specify the type of encryption. Maybe I'll try making some requests with different flavors and see if I can reproduce the 403. It's not working at all for me anymore so it isn't intermittent. I'll also try & reboot the hub & see if anything changes.
For fun tried to make a request from WebCore and got a 403. I don't think it proves anything because I think it uses all the same libraries, but just an interesting data point.
FWIW, I'm getting exclusively 403s as well from the Life360+ app in HE.
I thought I might try logging into life360.com and getting a new access token, but I can't even even log onto their website. Anyone else experiencing same?
Did some wireshark tracing of the app connection. Seems to be caching connections to https://api-cloudfront.life360.com for a while - no direct correlation between asking for location and a new TLS session cranking up. Interesting that the 403 coming back is not a session abort - the TLS session persists, the 403 status is not aborting the TLS session. New sessions seem to always negotiate to TLS 1.3 and other parameters in the server hello and client hello seem pretty normal. Rebooting of course forces new connections and doesn't seem to change the 403 response (expected, given above.) Of course, if the app is down, the 403 from the API might be expected. I don't have any other way to ask for the app to respond to know if it's up/down. In any event, it looks like the TLS sessions to https://api-cloudfront.life360.com are pretty stable/standard/nothing unusual I noted watching them (but, of course, I can't decrypt/look inside). Regardless, seems like the 403s are not TLS connection dependent but are application protocol issues within the TLS tunnel.
Played with it some more and confirmed it has to use TLS 1.3 pr it fails. But I saw the same thing about not aborting the session.
I did come across something interesting though. Using CURL on Win11 works perfectly every time. But literally the exact same CURL command on Linux (Debian & Ubuntu) fails everytime with a 403. This seems to imply (to me at least) that it has something to do with the libraries being used. Which would explain why HA works bc they use Python libraries instead. For the life of me I can't figure out what is different bc the the outgoing requests look identical but its the only thing that makes sense.
I'm not sure when mine started throwing the 403, but i suspect it might have been when i updated my hub. I'd be curious if anyone has tried with an older HE version. I'm on 2.4.1.155. Last time i know it worked I was on 2.3.something.
I use Manjaro (basically Arch) and curl fetches a valid payload for the user loction tested.
07:34:50.190621 [0-0] * SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384 / x25519 / id-ecPublicKey
07:34:50.320378 [0-0] < HTTP/2 200
Interestingly, I turned on the Life360 HE app to get the token to test curl - and it worked for two polls (3 minutes) then started to fail again.
WTF
that's just a local check in the driver to prevent accidentally calling the API too many times. I think when I was testing the schedule method to schedule the next API call sometimes it was returning too fast.. anyway, that's all this was for.
Thanks, given that after a hub reboot, the app appears to work for a brief time (fetch, etc), then the first error is the TOO_FREQUENT... followed by just 403s, I was wondering if there was a connection that created some sort of a lockout scenario.
thanks for digging into this! I haven't read everything in detail yet but it looks like you've got some good progress. Let me know if I can help test/debug anything
Hi,
I've read all the posts since December, seen several discussions, and seen that some have managed to make it work, which is not my case.
I followed instructions to remove everything via HPM, removed the drive, deleted everything, and installed it again, generating a new access token. At first, the installation didn't give any error, it recognized circle, place, members, but soon after it gave ERROR: fetch ?????: 403.
Any new instructions? I'm using the latest version 5.0.15.
And that's the strangest part. If you disable the app for a time, it'll work for 2 or 3 polls, then start failing forever. I don't know what the "timeout" is. I haven't done any testing other than leave the app disabled overnight.
That said, HA polls every 30 seconds, so it's certianly not a frequency thing.
My Wireshark trace the other day showed it frequently re-using cached TLS connections but not always. What I was looking for but couldn't prove was that reused connections didn't work properly. My hub is on WiFi however and it's more difficult to force all cached sessions closed. (Think that would happen if hub was unplugged from network?) Reboot would also close cached sessions and then work for a few times until it had some magic number cached and then start reuse and 403s. Theory sounds good but I wasn't able to prove or definitively disprove it. I'm traveling for a few weeks so am not in a position to retry further but maybe worth investigating, especially if you can watch it on NetMon or WireShare to verify caching behavior vs 403s seen in the log. (Note: Snooping (cleartext) TLS with WireShark is easy if you control the server but darn hard without special tools if all you have is the client. You can still see the sessions open, the server and client requests, the data passing encrypted, sessions killed (TCP RST), etc., so maybe worth trying.) Good luck - wish I was in a location where I could play with it a bit more myself.
Stop Life360+ 2 hours, back and:
ERROR: fetch circles: 403
ERROR: fetch places: 403
ERROR: fetch members: 403
ERROR: fetchMemberLocation: member:347xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx33b: 403
Current configuration:

![]()
Hi, you commented on cached TLS. I understand that the ideal would be to turn it off. In my case, the HE is via cable, so where can I turn off the cache you mention? Tks.
My cache theory would say that when cached session expire, then randomly you might get a new working session, which might work for a time or two and then quit. Seems to match your recent report.
I don’t know any way to disable TLS caching on the client side (the server does the caching to save its own resources.) I was hoping that disconnecting the connection to Hubitat would lead the server to fail a heartbeat request, but thinking about it, I don’t think that servers do that heartbeat work – they just release cached sessions after some fixed timeout, or, when they need the resources, or for a variety of other internal reasons. I just did an AI (Gemini) query on this hypothetical issue as causing our problem and it’s consistent with what the AI would expect. It smells like it’s right, but I don’t know what HE is doing that causes some server assumption about the state of a reused connection to be incorrect and result in a 403 – though a 403 for a variety of session ID or other authentication mismatch was in the AI notes. FWIW. AI notes attached below.
Potential Server-Side Issues Leading to Application Protocol Failure on Session Resumption:
While the TLS RFCs don't dictate how application data is handled, they establish the secure channel. The problem you're describing points to a mismatch or error in how the server manages application-level state associated with a TLS session. Here are some possibilities:
Why This Explains Your Observations:
From: noreply@community.hubitat.com noreply@community.hubitat.com
Sent: Wednesday, April 23, 2025 5:01 PM
To: Ferrell Moultrie ferrell@moultrie.org
Subject: [Hubitat] [![]() Custom Apps and Drivers/Custom Apps] [RELEASE] Life360+
Custom Apps and Drivers/Custom Apps] [RELEASE] Life360+
WMarcolin Owner
April 23
Stop Life360+ 2 hours, back and:
ERROR: fetch circles: 403
ERROR: fetch places: 403
ERROR: fetch members: 403
ERROR: fetchMemberLocation: member:347xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx33b: 403
Current configuration:
Visit Topic to respond.
To unsubscribe from these emails, click here.
Unfortunately, no matter how many times uninstall or update the Access Token, change the time, the 403 error persists. What was a great localization solution for HE no longer works, unfortunate.
Thanks,
Wilson
Just stopping by here because I happened to notice in HPM that I was not on the latest version of Life360+. I had given up on the app a year or two ago and I guess I hadn't ever deleted it from HPM. That got me excited that it might be working again so I followed the instructions with the access token and got all my members and places correctly fetched. But I get the fetchMemberLocation 403 error. Came here looking for help and see that it is toast again?
ETA: Well, after over 12 hours of connection errors, it connected for a brief moment at 5am, triggered all my "home" profiles which turned on the lights as if we'd just gotten home. Then, after a few minutes, lost connection again. Oh well.
I don't know enough about TLS sessions to add much to what you said. But, I am able to capture traffic between an actual Life360 device and server. The easiest way I've found is to use an app called HTTP Toolkit. It also requires a rooted Android device.
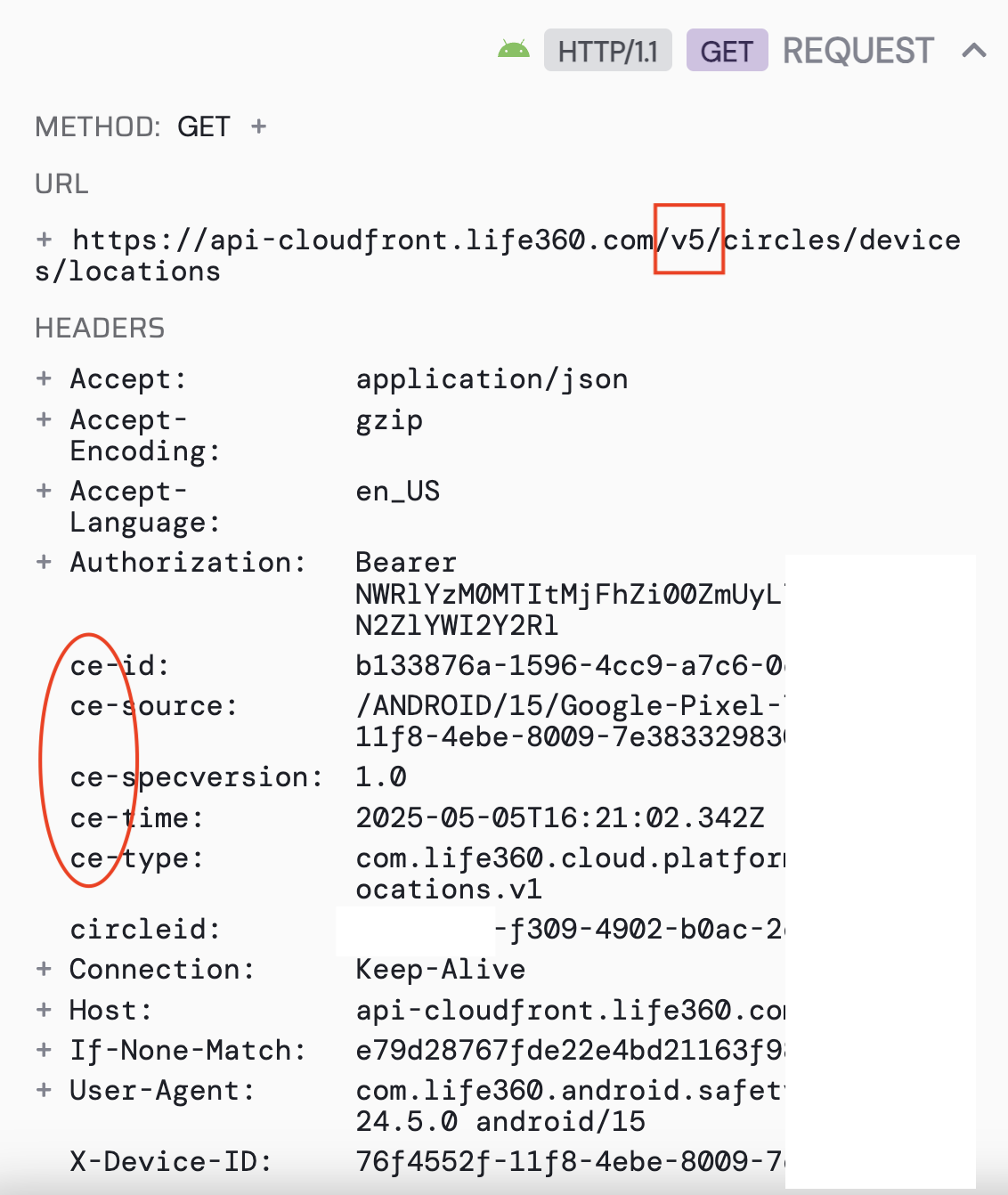
This is how I was able to figure out that newer Life360 clients are using a new /v5/ API. I had implemented it initially in the Hubitat app but after dealing with 403 errors I reverted back to the same older API's that Home Assistant was using. When that still didn't work it took some great work by @matt.palermo to figure out the hubitat app wasn't supporting cookies which did the trick.
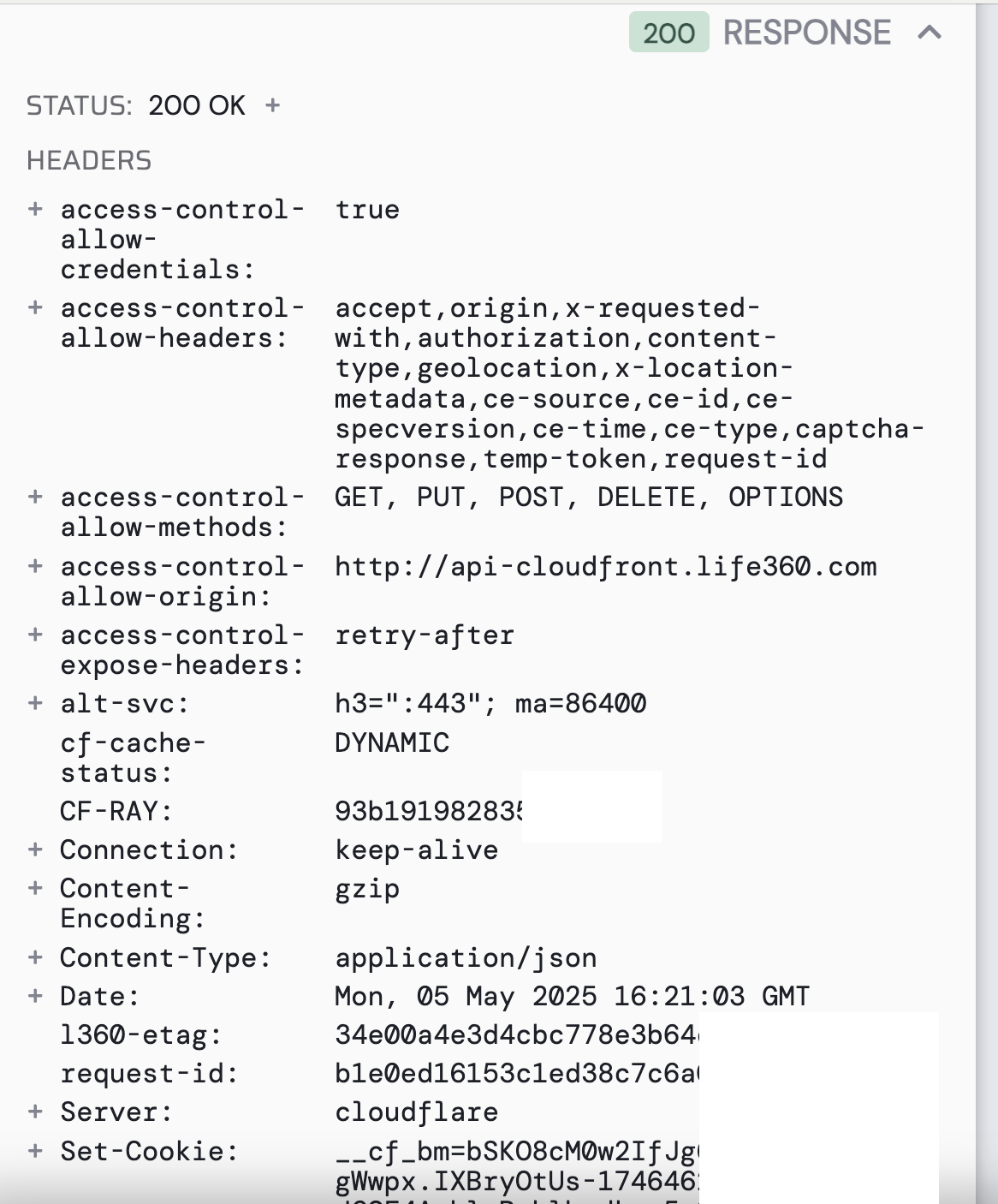
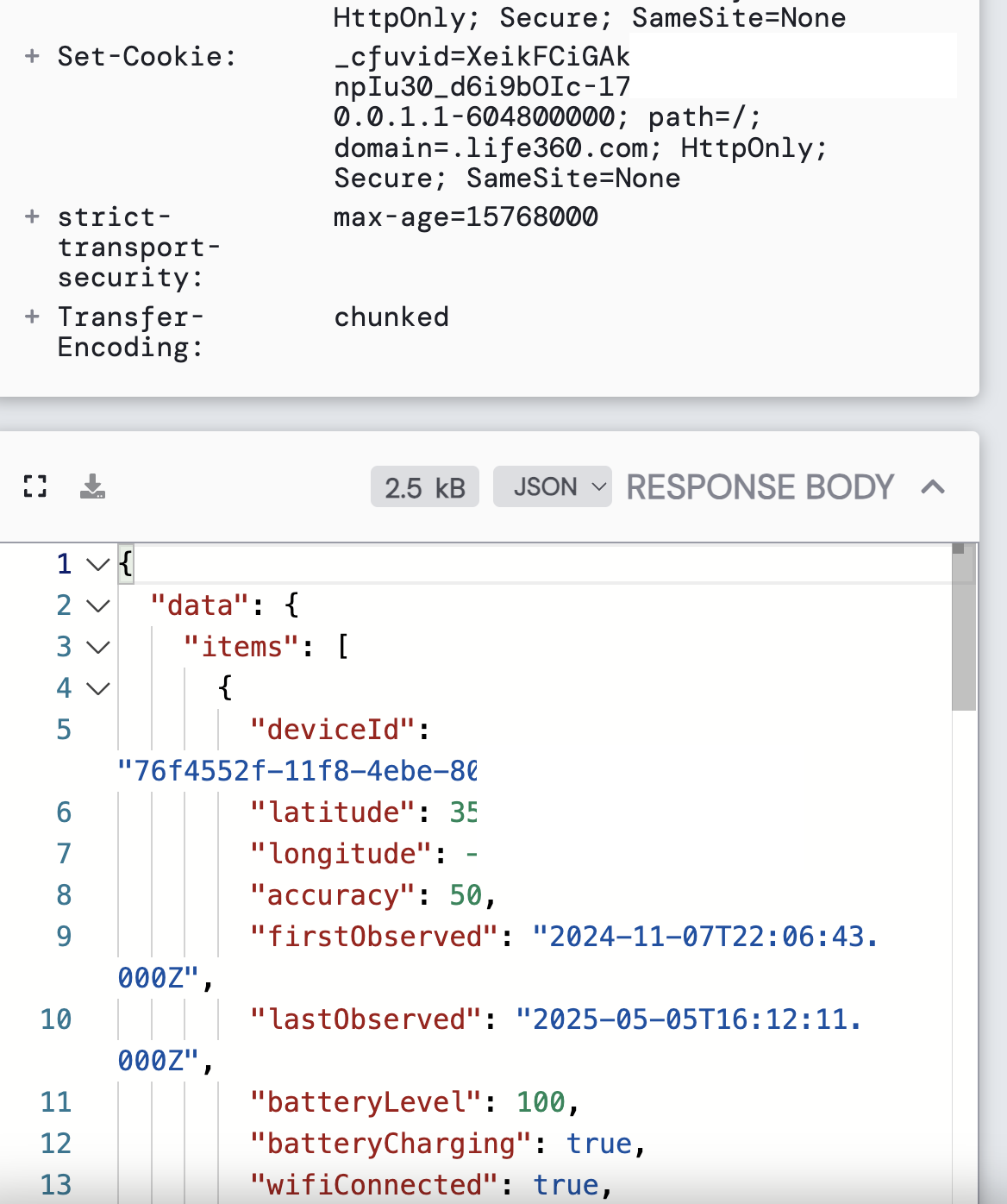
Here's what's visible in the response (the free version of HTTP Toolkit can't export to text so I have to use screenshots)
Anyway, I don't know if this is something worth trying again (using the newer API's) or if anyone has a hint of something missing from the Hubitat app.
Also, FWIW the http request headers that start with "ce-" are added for CloudFlare. They could be used to prevent access.
I don't have the home assistant version of Life360 still running.. is it still running for others w/out any errors? The theory was if Hubitat just matched HA then it should work as well. Maybe it was mentioned above but that'd be the first thing I'd want to know
I'm still using the HA version of Life360, works fine. Have not seen any issues or errors. I think there might be one of two things going on here:
When I make a request using CURL from a Linux box, it fails with a 403 everytime. When I do the same from Win11 it works everytime. What I found is after the inital authentication/handshake, there is a TLS renegotiation. The renegotiation wasn't working from Linux until I disabled ALPN, and then it worked perfectly. I'm wondering if this is why the request from HE might be failing? Maybe the groovy HTTP library's don't support renegotiation?
I disabled the HE Life360 App for several days because all I was getting were 403's. I renabled it to test something and it worked fine for an hour or so, then started throwing 403's again. It makes me think that it triggered the cloudflare bot protection. The CE headers you mentioned seem to support that.
I would love to see what the HE request looks like, but I'm not good enough with Python to find that piece of code. But obviously the are doing something different to make it work.
Also - when I make a request (via CURL or Postman) to the V3 or v4 API, I get a valid response. When I make a reqeust to the V5 API I get:
{
"errorMessage": "Missing or invalid ce-id",
"url": "/v5/circles.json",
"status": 400
}
One of the earlier versions which used the v5 API filled out these headers
As I remember it worked -- but so did the older API too.
I'm still using the HA version of Life360, works fine. Have not seen any issues or errors
This has always been the most interesting point to me.. if HA works without issue I feel like Hubitat should be able to as well. But, your points about TLS might might be 1 difference (not one I can help with though)
Download the Hubitat app