I notice that my Hubitat gradually slows down to the point it is unresponsive. There are two things I have done that I know cause the problem:
Maker API, call getDevices() via http every 2 seconds.
z wave poller polling a few (like 8) devices
A memory leak would explain what I see. Each HTTP request or poll of the z wave devices leaks a little memory. As the Hub runs out of free memory, it spends time trying to garbage collect or otherwise free up some memory.
To be more specific, when I turn on polling, for example, the hub is fast for a couple of days. Then routines start taking longer to execute. The WWW server/browser interface starts taking more and more time to load or refresh a page. Eventually, it takes 10 seconds or more, or becomes so completely unresponsive I unplug the hub and plug it back in to power cycle it.
I keep the hub software up to date. It's not something that started with any one software update. It's been going on for a year or more.
Maybe it has to do with logging instead of a memory leak. If it's logging all those http requests and polling events, handling growing log (files/lists/whatever) might take more CPU and/or I/O time.
I haven't been doing the HTTP request to get all devices for a long time. I've been using the Maker API post feature, as well as the event socket. So it's pretty much down to the z wave poller app.
FWIW, I make very heavy use of MakerAPI - with two instances on each of my hubs. I haven’t experienced any slowdowns. I generally reboot only for a platform update.
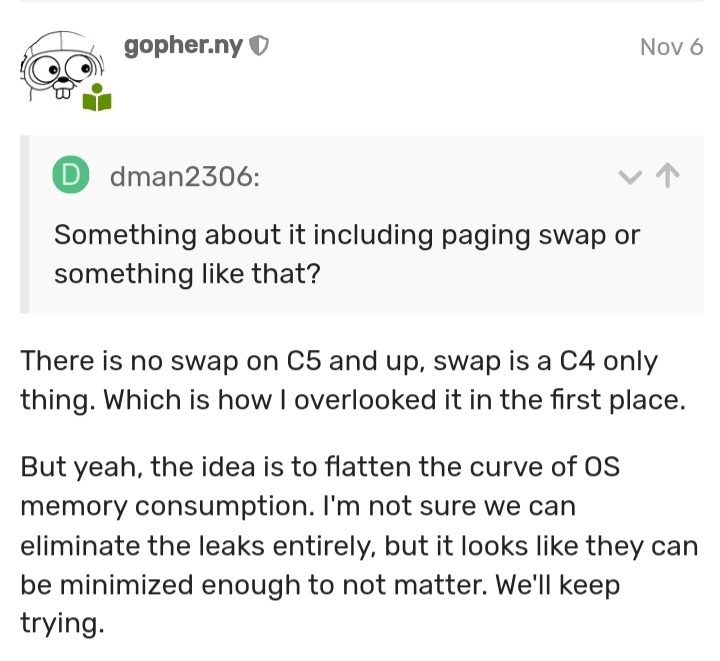
Mind me asking what model your hub is? We know that C4 has some problems. C5 experienced what you described, but recent platform enhancements have vastly improved this symptom, which as you pointed out is not new.
I'm currently going through all 50 devices and assuring event history is 100 and state history is 300 and enable debug logging and enable description text logging are turned off.
Heh... It was sooooo slow trying to do this for the first device or two that I ended up rebooting the hub. I had turned off the z wave polling and it was still slow. But after the reboot, it's pleasantly fast.
I have this set to 10 and 10. Makes a huge difference in database size. I have not had any reason to go back through the events farther than that yet at least, just need enough to keep motion lighting working properly. I am pushing around 200 devices on each of two hubs and only reboot with updates. I'm not doing any polling though as most of my devices are zigbee, with about 20 z-wave plus.
Care to share what the problem might be and if a fix is being considered? I am seeing this on a C4. Just don't have the time to migrate 200 devices to a new hub.
It is not one fix, it is the tremendous effort that has been put forth by our engineers to curve the memory consumption of the operating system. If you remember, not too long ago, everyone had to reboot hubs every few days. That is now a thing of the past. Unfortunately, C4 is different hardware than C5/C7 that runs less efficiently.
There's a strong correlation between apps/drivers that report long total running times and memory consumption. The fix could be as simple as increasing dashboard refresh intervals, but that depends on what stats say. It could be more involved, but let's try easy pickings first.
BTW, we're working on a easier way to access this information. There's much more troubleshooting value to it than first thought.
Also, event and state history values can be set to much lower numbers unless you have specific uses for them.
No, although this is helpful for a different reason.
The stats I'm referring to are driver/application runtime stats. They are disabled by default, so they need to be enabled first with http://hubitat.local/hub/enableStats endpoint, and results harvested later with http://hubitat.local/hub/stats endpoint. The report is an unsorted, hard-to-read collection of app ids and numbers. Within that, there are total times of how much time each app/driver took to run. In case of problem hubs, there is usually a standout or two that takes a big chunk of hub's resources. Here's an example of an overactive app:
app id 22 runcount 24930 total runtime 11073887 average run time 444.1992378660