Severe CPU load is being detected and altered via System Messages but I don't find a corresponding entry in Past Logs so how am I supposed to know when the incident occurred or what caused it?
I believe these events will show up in "System Events," likely "Hub Events," but I do not believe they show up in "Logs." If you're seeing the notification pop up on your hub, however, it should mean that it was pretty recent, since it should get cleared some time after.
What is causing it is another story.  You'll have to do some work to figure that out. Your best bet is to look at the new app and driver statistics under "Logs." My advice: see if any app or driver is either running a lot of times or for a long time (particularly one that doesn't have a good reason for doing so--all of them aren't necessarily bad; and likely a custom app or driver before a built-in one), and go from there. You can disable apps or drivers for the purposes of testing, in case you did not already know: Apps - Hubitat Documentation.
You'll have to do some work to figure that out. Your best bet is to look at the new app and driver statistics under "Logs." My advice: see if any app or driver is either running a lot of times or for a long time (particularly one that doesn't have a good reason for doing so--all of them aren't necessarily bad; and likely a custom app or driver before a built-in one), and go from there. You can disable apps or drivers for the purposes of testing, in case you did not already know: Apps - Hubitat Documentation.
It would be nice if the CPU load was live and in the Apps and Devices statistics.
That way one could look at the logs when the high loads are occuring and troubleshoot.
Or, maybe just create a system entry on a regular, user selectable basis, so one can norrow down the issue with a log cross reference.
Incorrect. There's nothing in the Hub Events list about CPU.
I mean, check "Location Events," too, but I (luckily) haven't had any of these events so can't check for sure. That was my best guess, and I couldn't find any posts about if/where it may actually appear besides the notification bubble.
What I do know works is that Rule 4.1 can subscribe to these events (as a trigger), so if you wanted a device notification or something when it happens--or you could log a message yourself in the rule--that would for sure work.
1 Like
severeLoad events are present in Location Events but the Value is never greater than 2.99. What is Value?
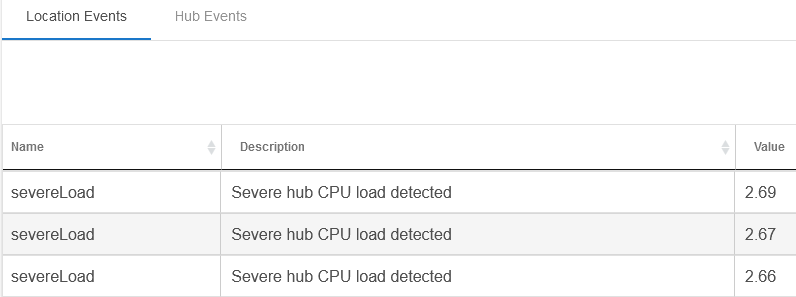
That I don't know. I'll defer to @gopher.ny or a community member who might happen to know, but my guess is that the threshold for the alert is more or less arbitrary, though one they happen to think is likely to be concerning, (Unless, from what I recall them mentioning, you didn't recently did something intense, like rebooting the hub and letting apps/drivers initialize--if it calms down on its own in short time. Rebooting is otherwise a good idea in this case.)
If I had to guess, I would bet that is the cpu load average, like what you would see on a Unix based system. I believe the hubs are quad core, so a value of 4 would effectively reflect that all 4 cores were busy.
The number is 15 minute average load as reported by uptime Unix command.
Here is the detailed explanation of those numbers, perhaps too detailed...
In a nutshell, number 2 means that hub's 4 CPU cores are 50% busy over 15 minutes or longer. Consistently high loads come with a possibility of thermal radio shutdown.
2 Likes
Thanks for sharing the reasons why high CPU load are reported @gopher.ny, perhaps it would be worth making this a thread of it's own, including any similar thresholds that trigger warnings? Unless there is a thread that already outlines this...?
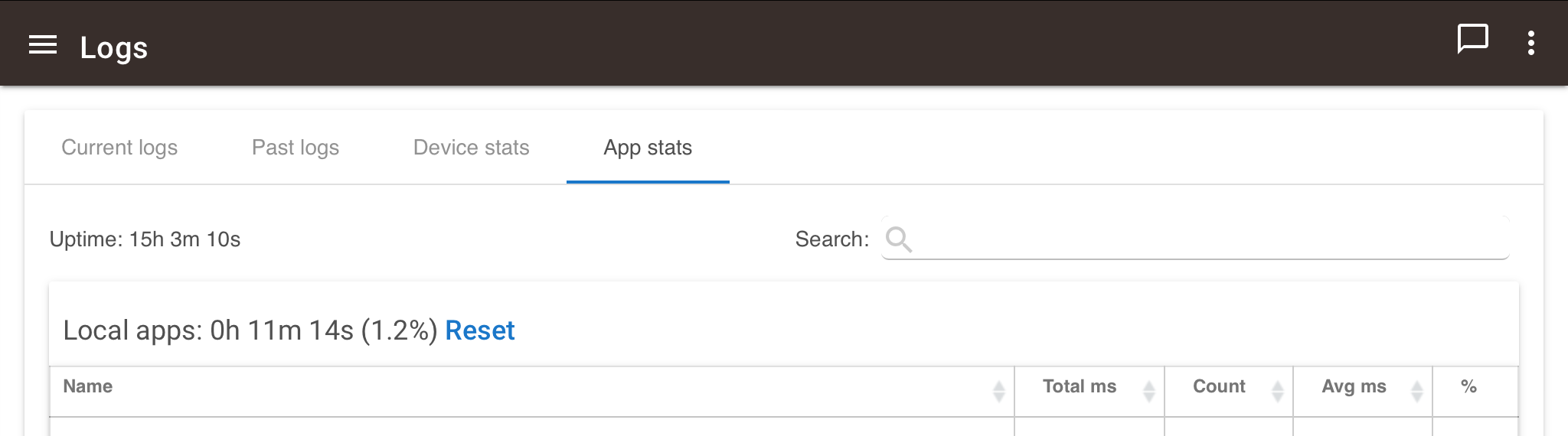
To see which apps/drivers cause high CPU load, check out Logs page, Apps and Drivers tabs. There are some useful metrics there, although most columns are hidden by default.
3 Likes
So how do we unhide the hidden columns?
Use the checkboxes at the top of the page to toggle the display of the metrics you're interested in.
2 Likes
Could be right, I don't have 2.2.5 to test on anymore. Hope I didn't give away any secrets, but mod my post if I did, I suppose? 
As you are using 2.2.6 (beta) at least we know something is coming soon.
What other juicy bits are in there? 
Nothing interesting to see here, move along...
3 Likes
Just need to keep an eye on the threads popping in and suddenly disapearing as the beta testers forget to post in the beta only categories. ![]()
1 Like
Bit of a side query while following this.
Logs show Uptime: 2264d 19h 14m 33s and I shutdown yesterday and have only had the hub for 2 months, not 6+ years
Someone else reported this in another thread.
Can't remember what the answer was though. Sorry.

