Every few days my hubitat keeps becoming unresponsive - stops running rules, can't reach through URL, or even reach the diagnostics site page on port 8081.
Works fine after a hard reboot (pull power and plug back in).
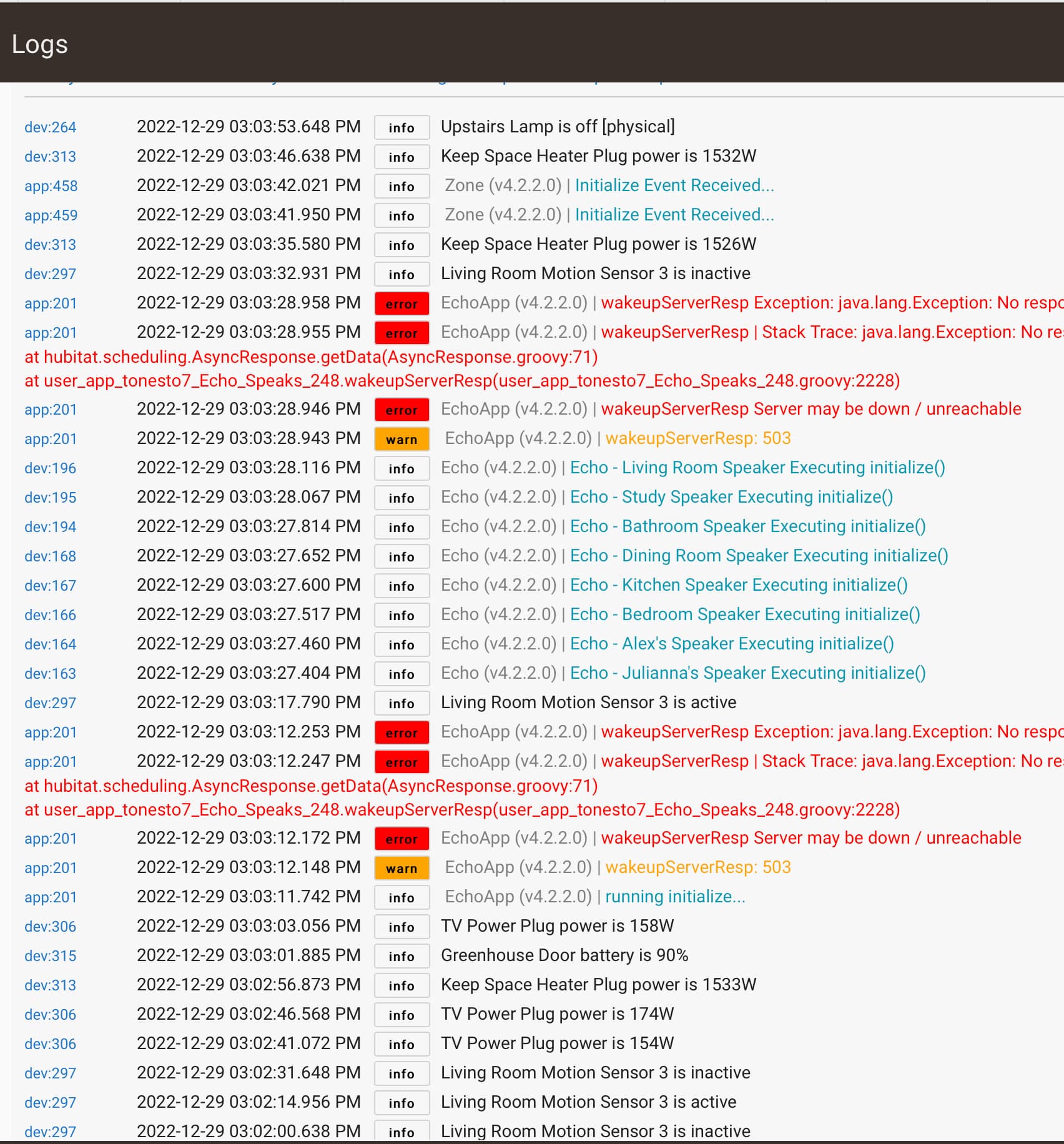
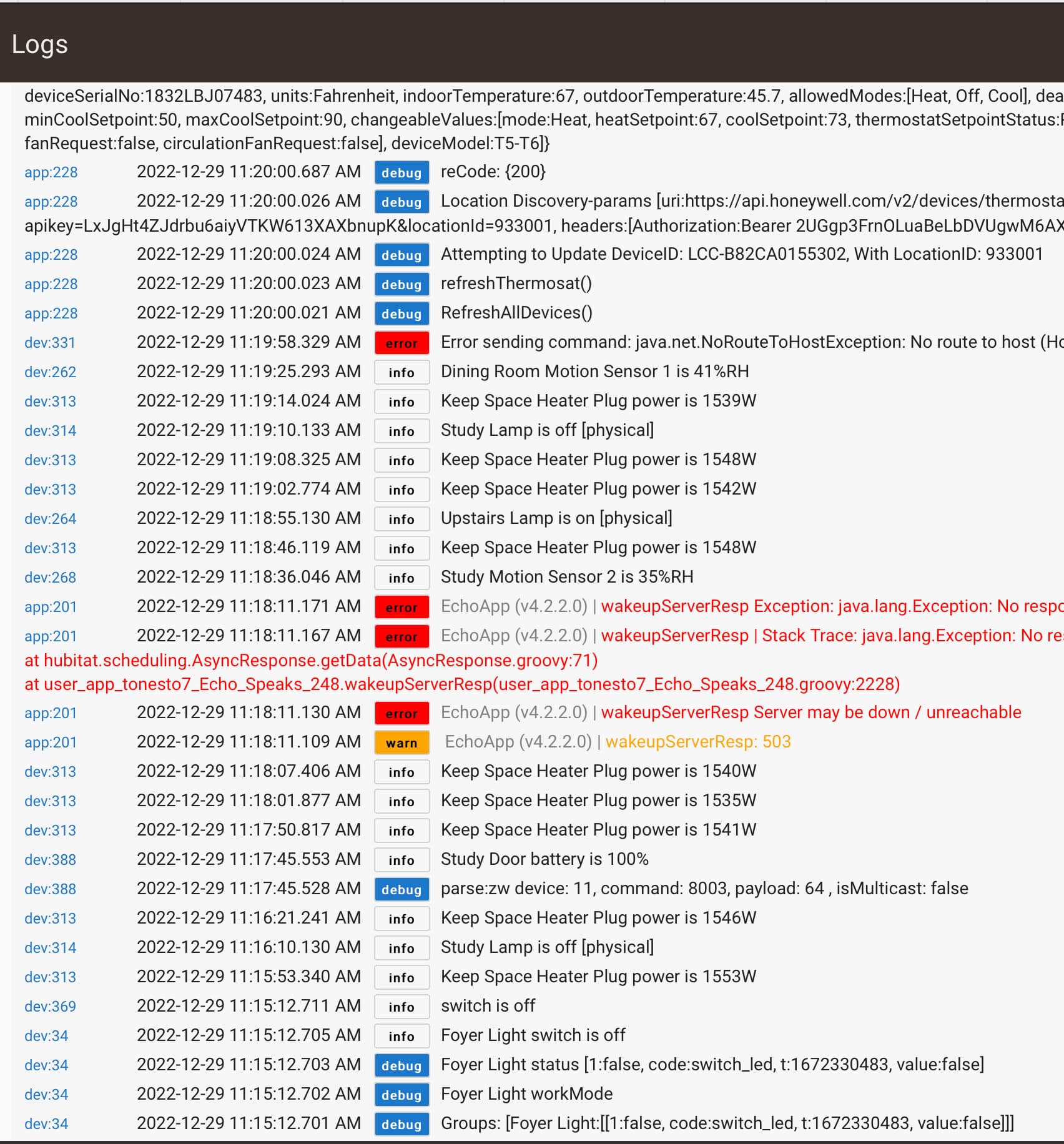
I've looked through the logs and see EchoSpeaks has quite a few errors, but not really sure what I'm looking for or a clear cut cause.
I was hoping someone would be able to lend their expertise to help.
Is there a known issue with jumbo frames?
My hub locked up unexpectedly with the same symptoms (not even pingable) and all the logs were clean. After 2 lockups, 2 power cycles, and an eventual db restore it's been stable but I have no idea why it locked up in the first place. This would at least give me something to look for. Thx
There’s a known correlation between random lockups and devices sending jumbo frames on the same LAN. One solution seems to be to isolate Hubitat hubs on a VLAN where jumbo frames are not used.
No jumbo frames enabled on any of my router/bridges. All MTUs are set to 1500. I can't think of any device that would be using jumbo frames. I checked my NAS and it's set to 1500. Any tips on discovering if a device is trying to use jumbo frames on the network? Not sure if that even matters because like I said, 1500 is the max at the router.
I had been using Heroku until they shut us out. I'm not paying for the service, so right now my EchoSpeaks is just giving a bunch of errors. I've been meaning to setup a local server on my RPi but haven't had the time yet. The problem predated Heroku pulling the rug out from free service, however, so I didn't automatically think it was that causing my issues. I guess I can rm echospeaks and disable all my routines that use echo speaks to see if that solves the problem.
I disabled the echo speaks and removed it from all rules and webcore pistons that were using it. I even moved the hubitat over to a different hardwired switch on the network. I've still have had to restart Hubitat twice since this time due to unresponsiveness.
I tried looking into zwave and zigbee specific logs, but I must not have them enabled because it doesn't show any historic values, but they do start loading in if I leave the browser open on the "log" page.
When I look through the main hubitat logs right before hubitat stops working, there doesn't seem to be anything specific or consistent to what causes it to be un-responsive.
At this point I'm just thinking of putting the habitat on a smart switch and then if my Home Assistant/rpi can't ping it, I'll just have it turn off/on the smart switch. It would temporally solve my problem, but not a great final solution.
Any other options? Do you think it could be the hub itself? I never had this problem when I was on smartthings.
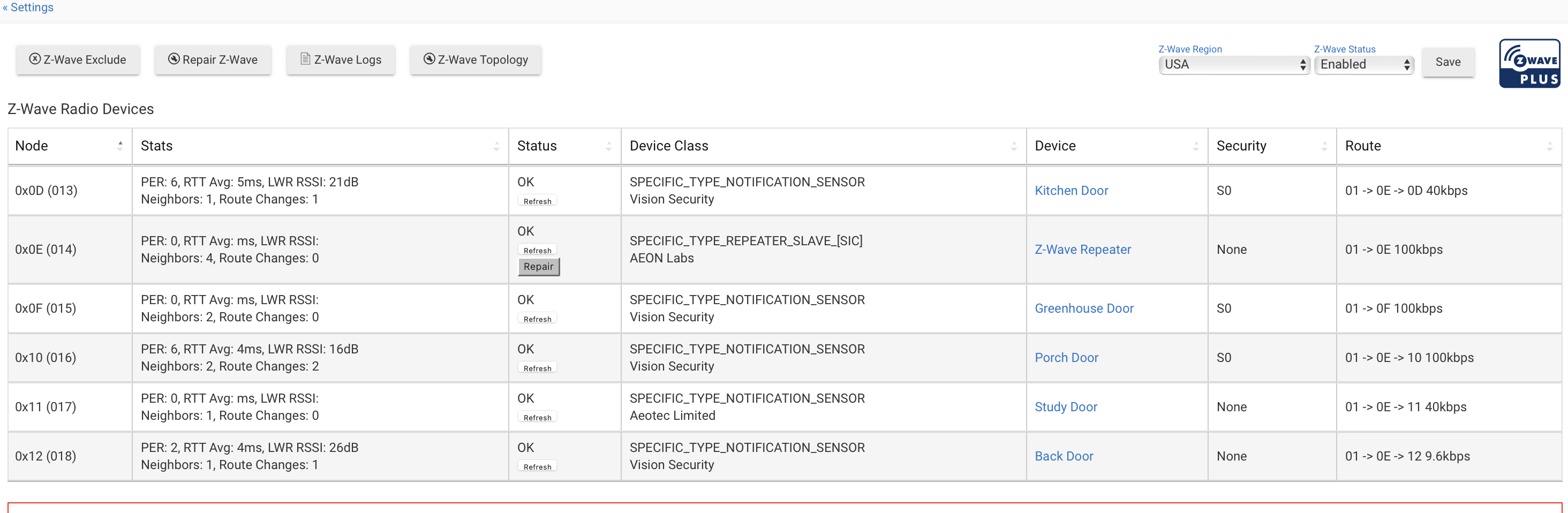
The problem with this is you could corrupt the database.... What do your device stats and app stats say? What other apps do you have installed? Have you done a soft reset? Is your hubitat set to Fixed 100 or auto in network settings? Is it set to DHCP or Static ip? Can you post a copy of your z-wave details page?
Perhaps start with the first 1-3 of @rlithgow1 's excellent questions....
Before you get too nostalgic for your SmartThings days, let's start by working out what the issue is. The move from the cloud to local processing takes some care and attention, and not always a result of solutions developed by the Hubitat team. Us amateur developers can, on occasion, increase the load on the hub.... But let's approach this with a scientific lens, basing our opinion on what we find.
Update from my end. Been up for 6 days (longest in 3 weeks), fingers crossed, so far so good. I've had 3 tabs open (ZW logs, regular logs, and the hub info) to see what was happening when (if) it crashes and everything's still been clean, like always. I'm really hoping it was the power supply but that just seems odd.
Hey! To answer some of your questions...
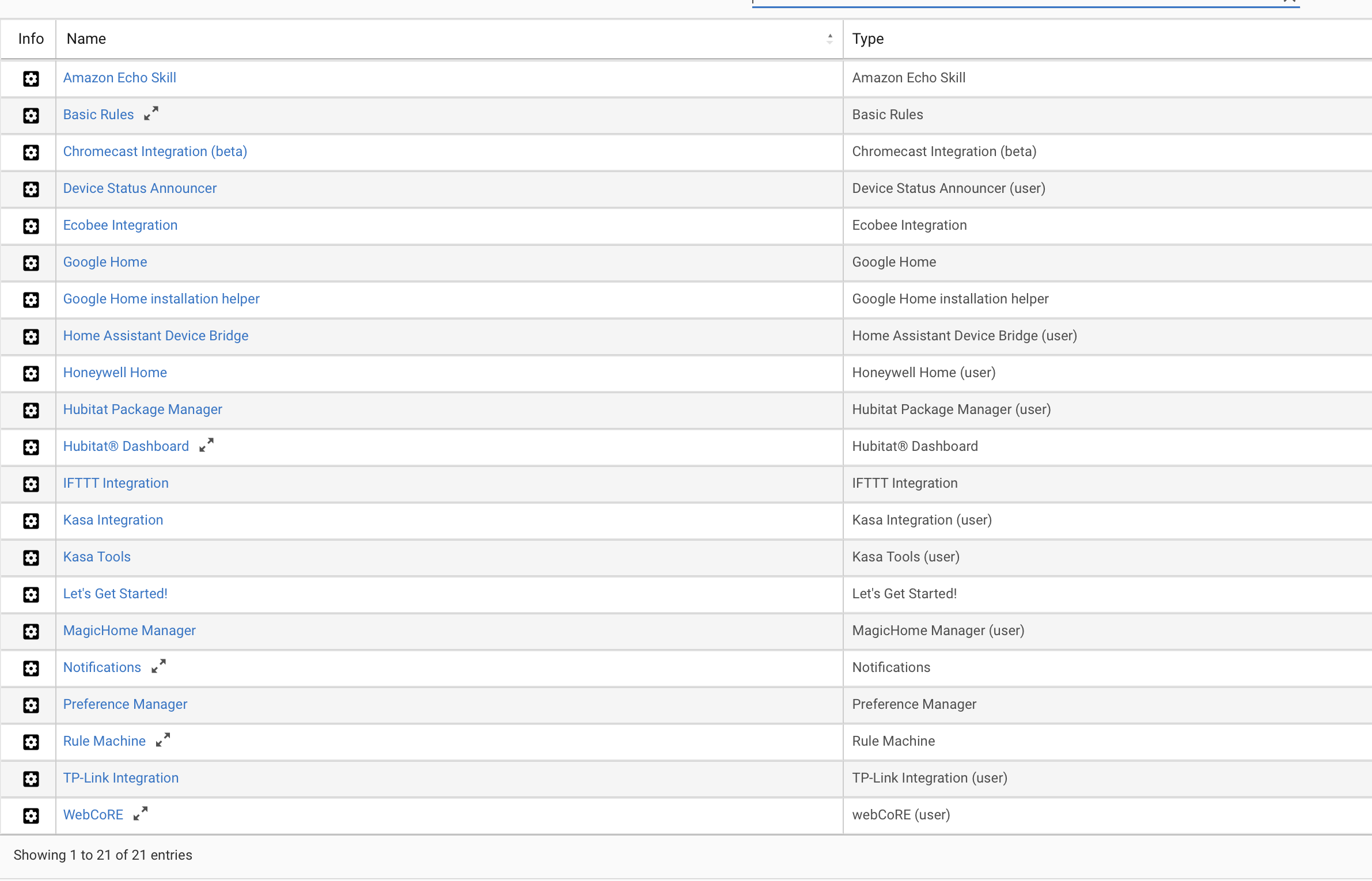
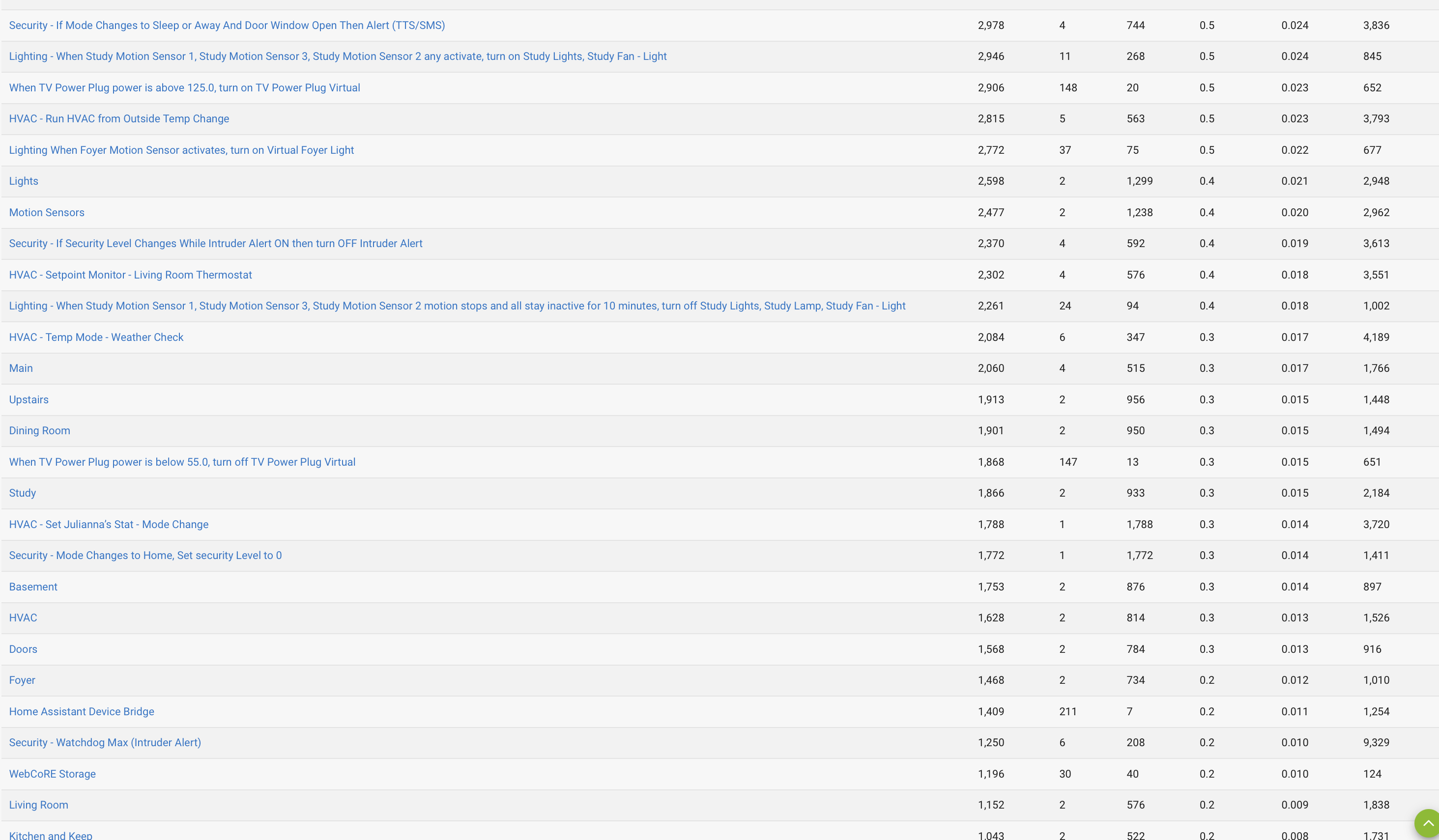
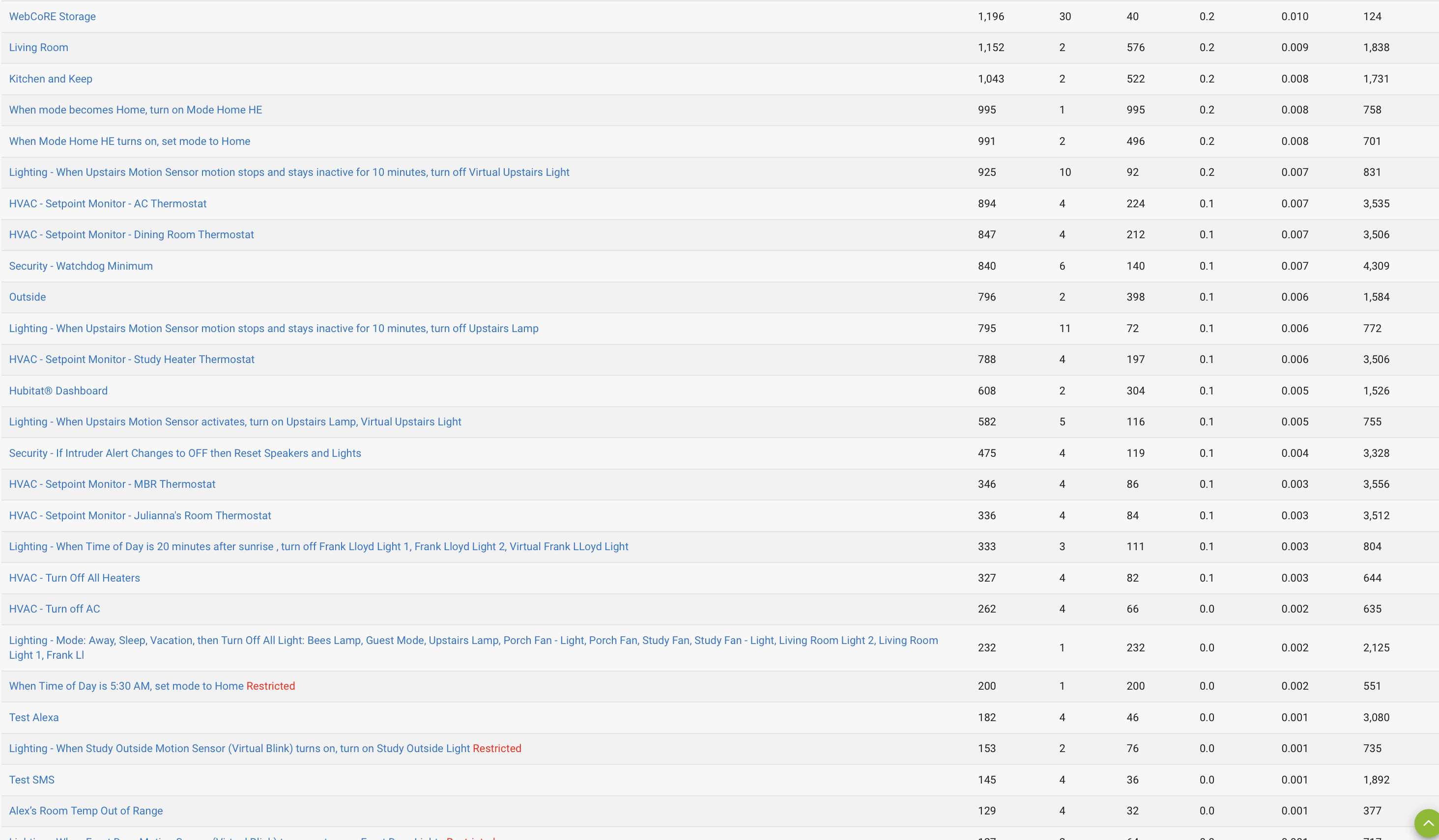
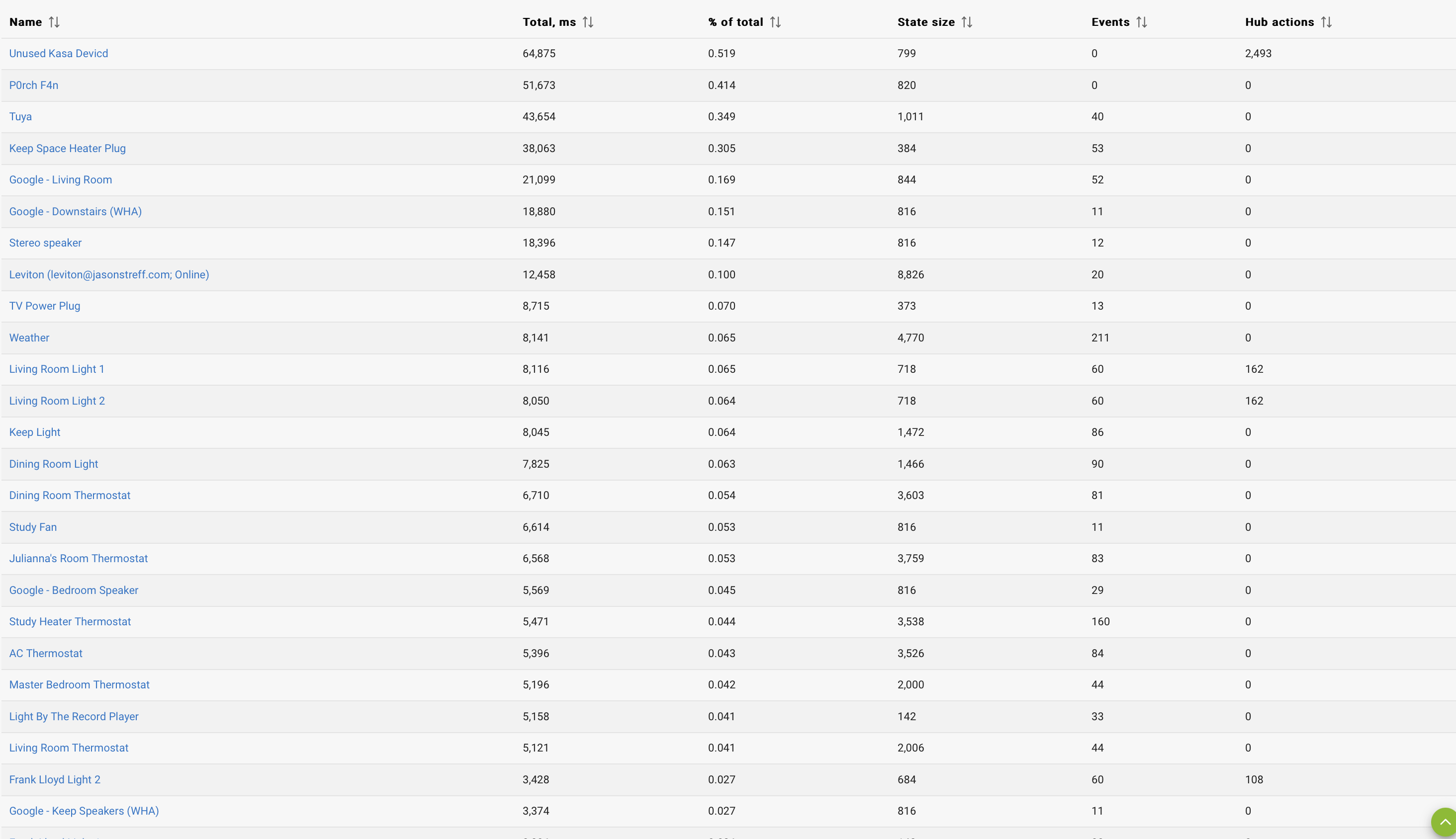
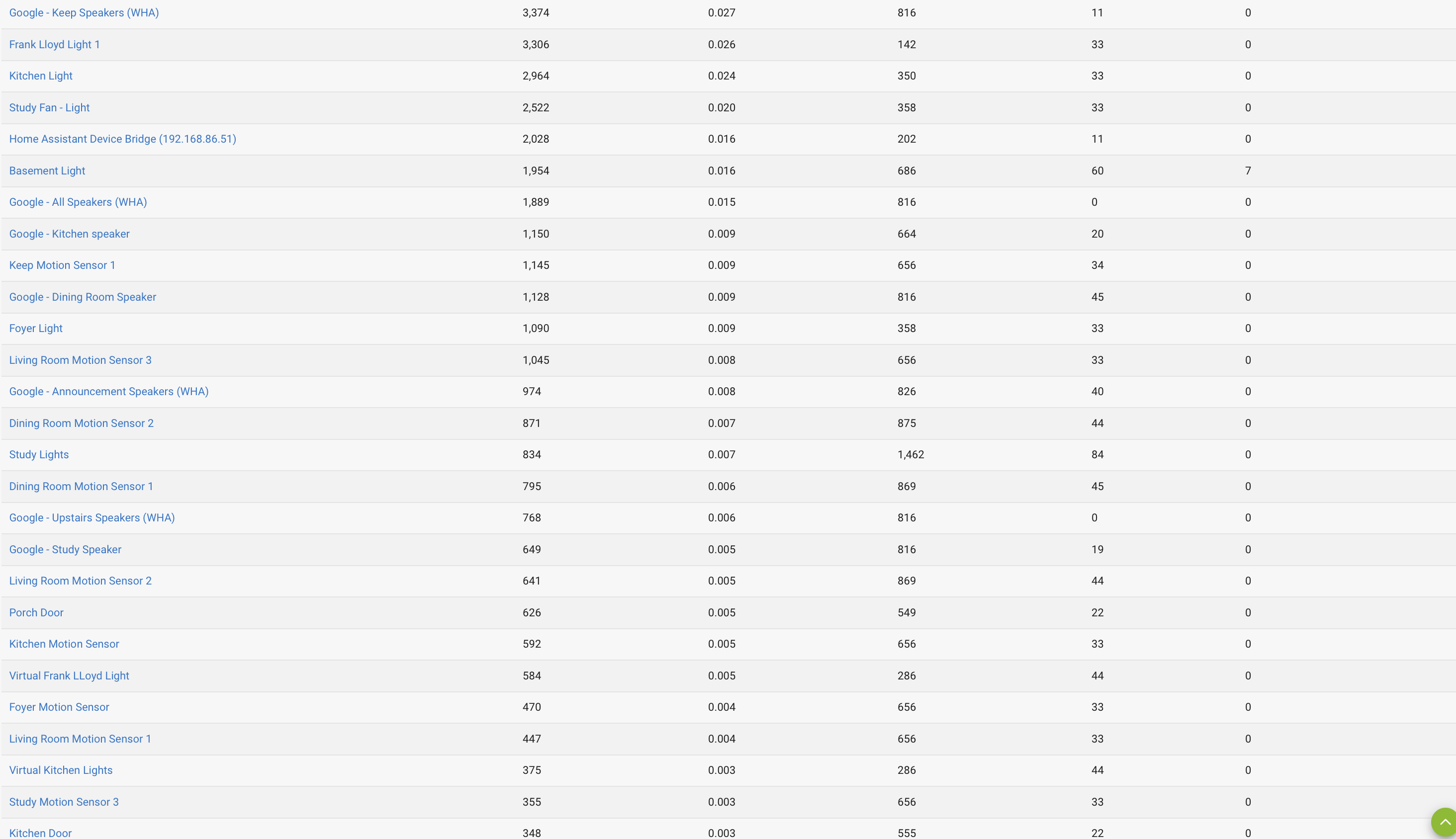
1,2,&6. Please see attachments for Apps, App Stats, and Device Stats
3. I have not done soft reset. It's my understanding that I'd have to then re-add all of my devices and then update all of my rules with a new devices. I hope I'm wrong! I've been afraid to do that because that's hours and hours of work and I'm not looking forward to that.
4. Hubitat is set to Fixed 100
5. Static IP with hubitat and at the router
Really appreciate everyone's help with this.
And I know that restarting it can cause the DB corruption, but that's my solution anyways when it locks up like this because there's nothing else I can do to get it working again.
You do not. The fastest way to do a soft reset and ensure there is no corruption is to restore the previous day's database. You won't lose any devices.
Please change that to auto
Make it either or, not both. Recommend just set the reservation at the router and leave the hub on DHCP. (Press the button on the bottom of the hub for 7 seconds using a toothpic or paperclip. It is the only round hole out of all the square ones)
When it has locked up can you get to yourhubip:8081 ?
Just to update everyone. The problem seems to be resolved.
The hub has hd an 8 day uptime since making the changes suggested by rlithgow1 as well as running a script from gopher.ny to slow down the CPU.
I'm not sure which of these solutions was the fix, but it does seem to be fixed or at least significantly improved as it had previously been crashing ever 3-4 days.
Big thanks to everyone for their time and suggestions.