Well I have about 100 rules. The two new ones that I wrote in connection with the new Kasa RGB strip light are below. This strip light is a parking guidance light that is red when a beam at the garage entrance is blocked and green when clear.
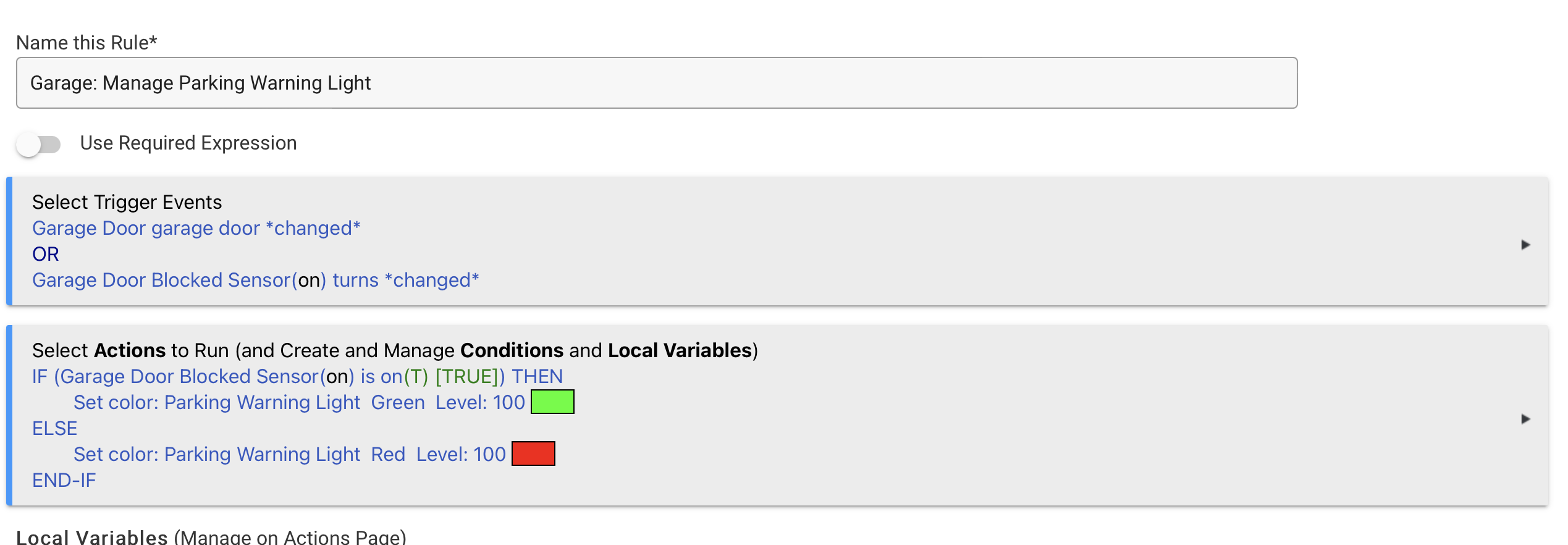
and
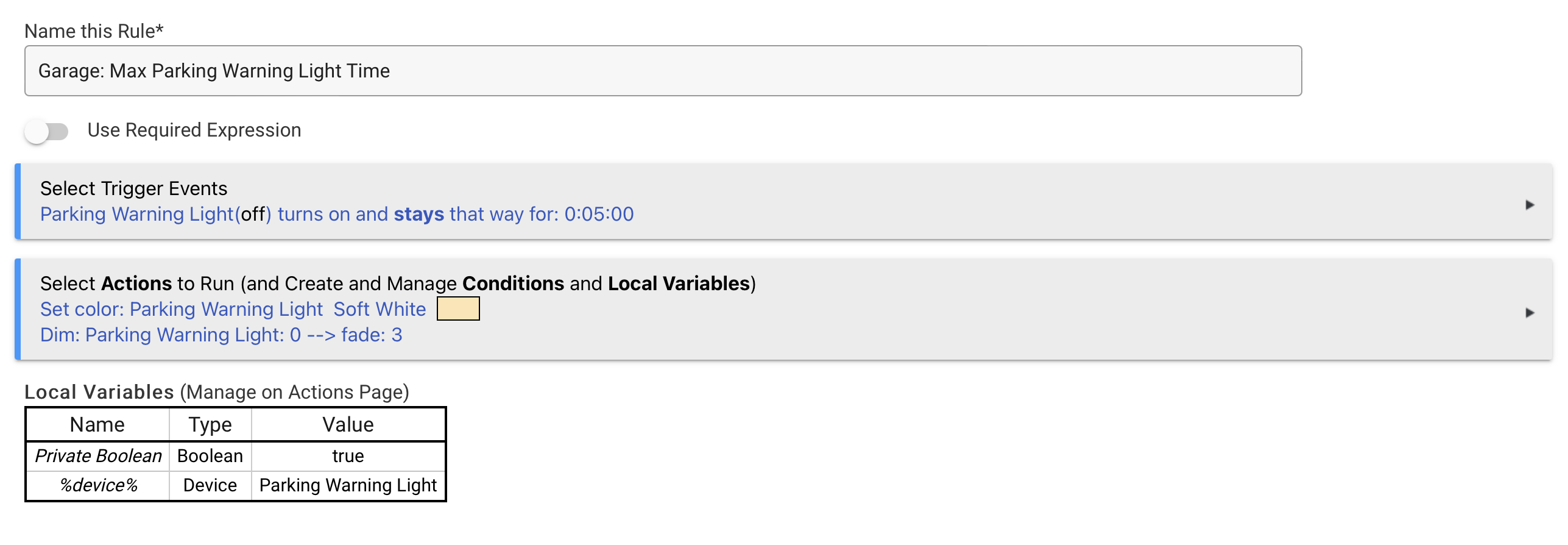
This is a (very successful!) riff on the project in this thread: Garage Door Blockage Indicator System

