Thanks for the reply sir. As the Hub did come back after a reboot with all devices and rules I will wait to see what Bobby suggests. I did do another backup this morning just to have a fresh one on file. Thanks again.
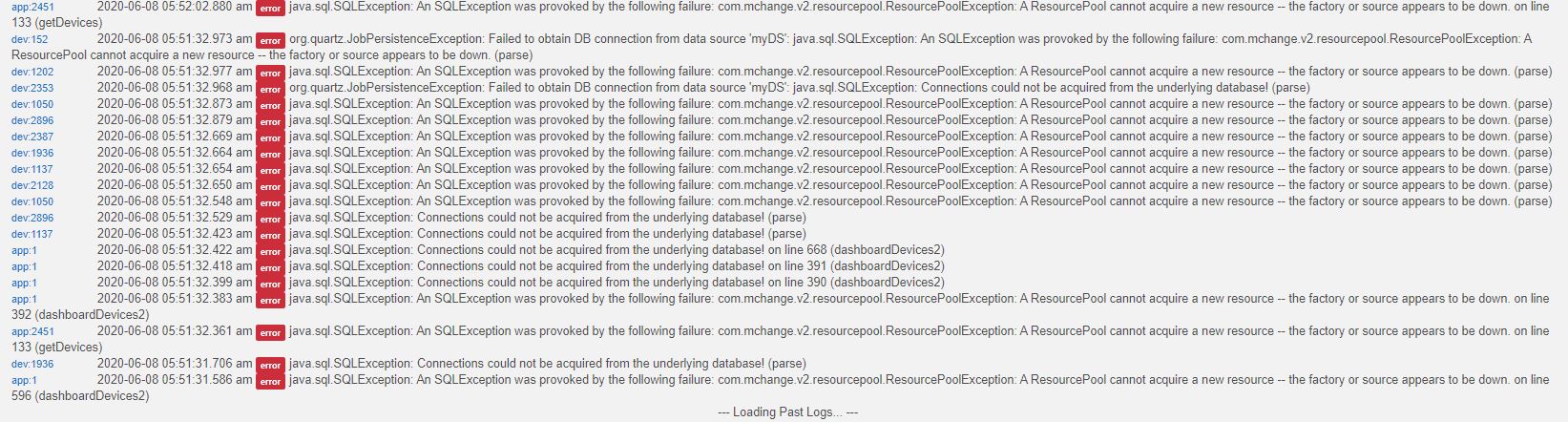
I had the exact same thing happen last night! I had never seen these errors previously. I was able to restart through the standard web interface (though received a 500 error on the main page). I'm running 2.2.0.132 on a C4 hub.
Sorry for the troubles. If you didn't do so already, please run the Soft Reset and restore a backup from your hub (second before last should be from prior day). Those logs are indicative of a corrupted database. At this point, there are likely too many errors flooding your hub, so is hard to know what may have caused it to crash.
@bobbyD I rebooted this morning, though did not restore. I have not had single error in the past 5.5 hours. My past logs still go back to to 8pm last night, well before the first error at 2:30am. I can attach them here or send them in if they would be helpful.
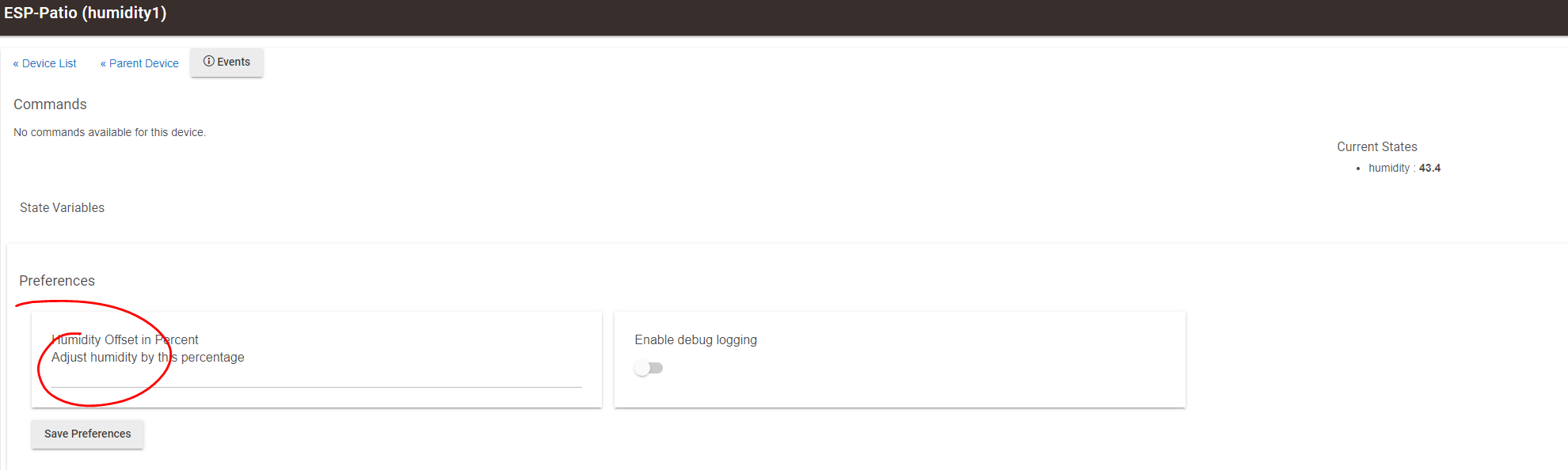
This time, I did not get the "nan" value after the storm caused by the backup, so I can say with high degree of certainty that whatever got scrambled, has to do with the offset routine. @ogiewon
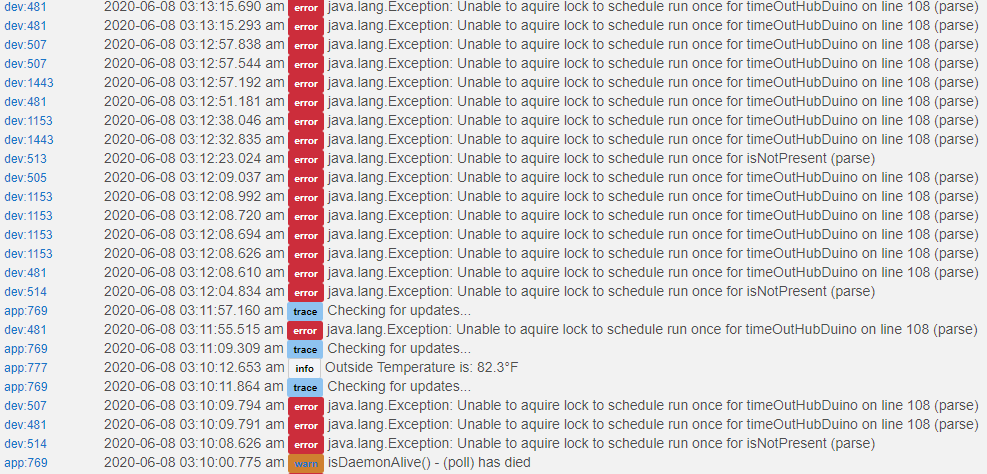
Now the standing question is, why the heck the backup is inducing this cascading effect. I was awoken at 2:30am last night (terrible tooth ache) and my arduino at my room, who has an led aka night light did not trigger its supposed rule action with the movement sensor. And the above Hubconnect message stating that it had lost ping to its SmartTHngs hub suggest total network isolation.
Maybe the fine folks from Hubitat Support could throw us a bone here. @bobbyD
I don't think this is the case. The offset for a sensor is literally just a simple bit of addition in the Child Driver.
What Hubitat Platform version are you running? There were some changes in a recent release that optimized the nightly maintenance performance. Many users saw a significant improvement.
Also, a Soft Reset may help your hub. Just be careful to follow the instructions very carefully and have a backup of your hub downloaded to your computer before starting. Do NOT perform a full reset.
Thank you for looking @ogiewon. I am always at latest. Maybe I should give the soft reset a try and see what happens.
But since I don't have logs at what happens behind the scenes when the backup takes place, I would like to understand if what is going and if its going to make a difference. @bobbyD is there any way that I could retrieve raw O/S logs for these backup events, or can I just stop them indefinitely? All LAN routines and Zigbee are falling apart for one hour when this backup is taking place. Not only Hubduino, but also HubConnect, Zigbee Presence sensor, Ecobee API, whom are bullet proof otherwise.
Understood. A Soft Reset might help...and it should not hurt. Just follow the steps in the Hubitat Documentation. Since this rebuilds the Hub's internal database from the backup you take, many users have seen improved performance of their hubs. Since the time you're issues are occurring coincides with database maintenance, a soft reset might be helpful.
Sorry for the troubles, you may have been running with a corrupted database. I recommend performing a Soft Reset as suggested by @ogiewon. If the problems persist, please reach out to support@hubitat.com, if you didn't do so already.
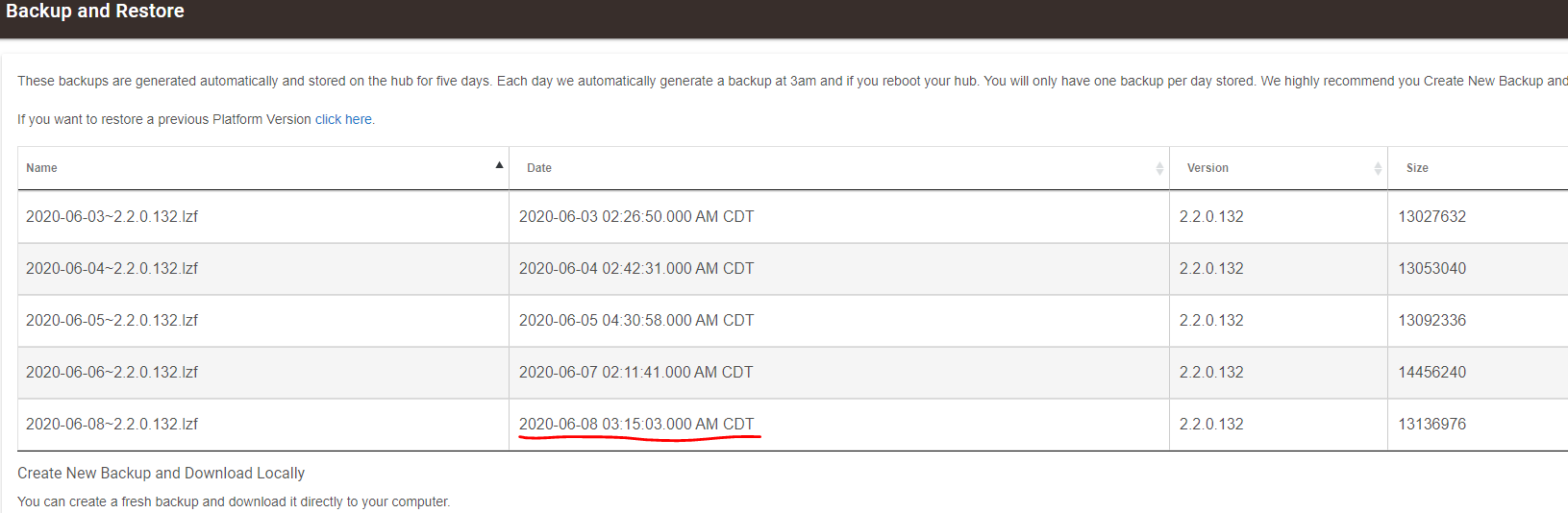
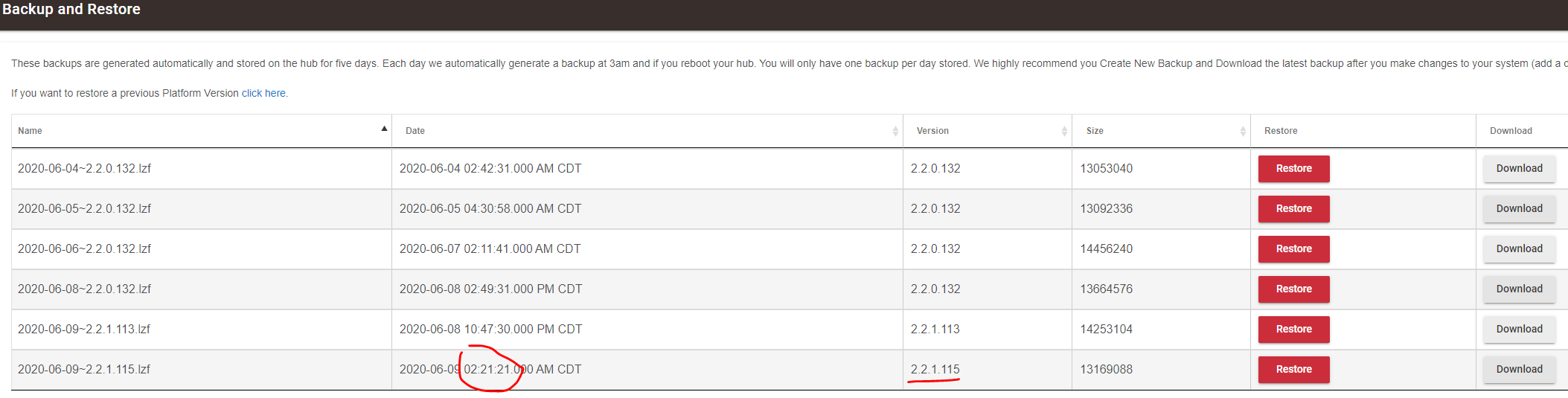
My hub backups are usually created nightly at ~2:20am. For today (June 8) my backup shows a timestamp of 08:40:17, which is about the time I rebooted this morning (System Events show a startup time of 8:41:31).
I've had no additional problems since rebooting, today. I'll be curious to see what happens tonight.
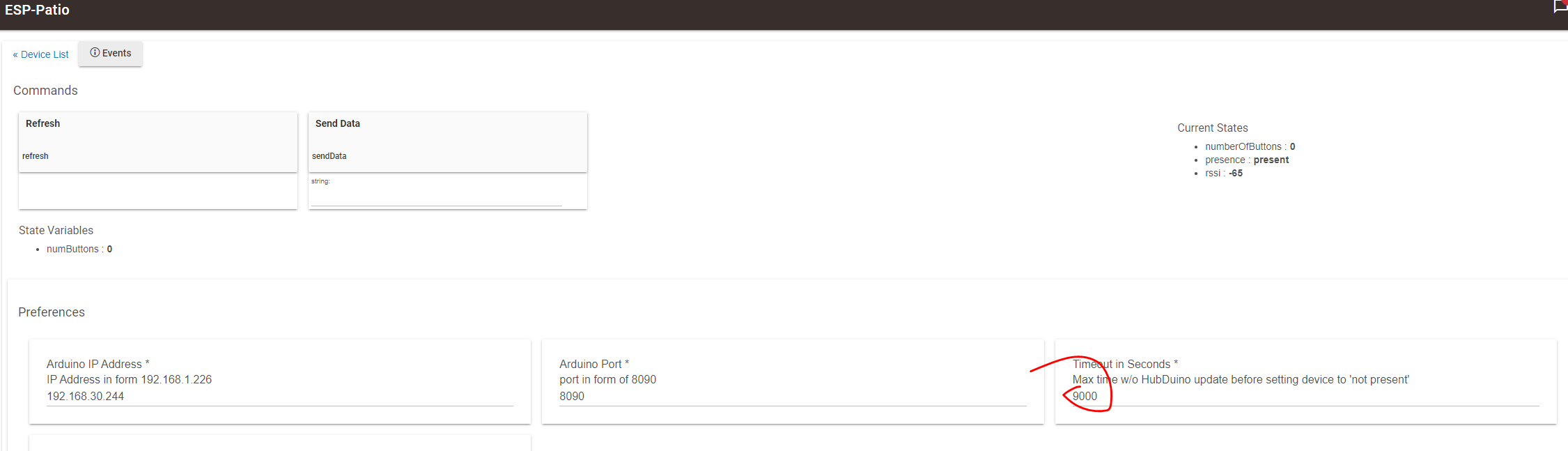
@manuelangelrivera - Glad to see things a re looking better. I am curious about your HubDuino/ST_Anything Arduino sketch. Do you have any polling sensors set for a relatively quick polling intervals? The fact that you received those two errors during the hub's automatic maintenance period, within 2 seconds of each other, indicates to me that your HubDuino board sent two updates to the hub back to back. Thus, I am curious about your Arduino sketch. If possible, I would love to see a copy of your sketch, with your WiFi credentials redacted of course. Understanding the problem will help me make improvements. I am already thinking about altering the current design of how the Parent Driver detects whether or not the device has stopped sending updates (i.e. how to update the Presence attribute, which is what is causing the error in your logs.) Thanks.