In Release 2.1.5.123 there is a new advanced feature in Rule Machine that allows you to extract a token from a string, including from a String Variable.

Notice that the string used above is 123-456-7890. The Delimiter is the character (or characters) that will be used to break the string into tokens; "-" above. The index selects which token we want, starting with 0 for the left-most token. So, in this case, the result stored in Charlie would be 123.
That's not very useful as shown, because obviously we know what the first token of that string is. So, let's try a more advanced version of the same thing:
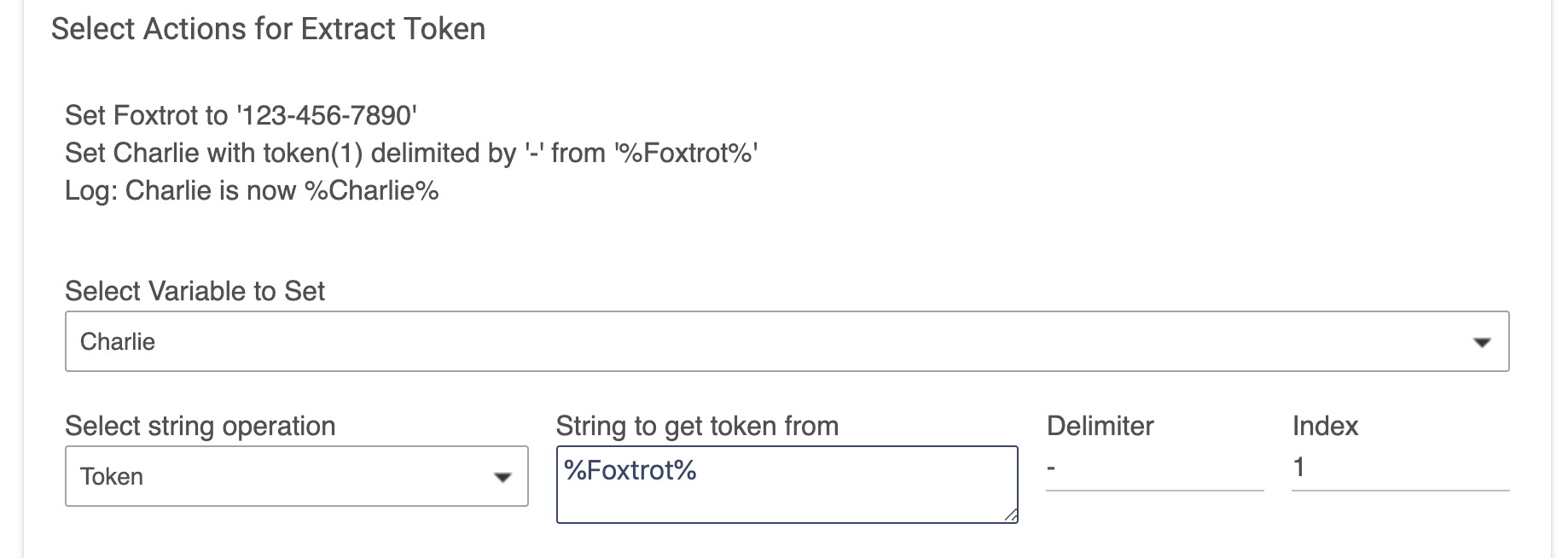
Now, in this case, the String Variable Foxtrot holds a string, and we can pull the tokens out of it, where the tokens are separated by "-". This time we would expect to get 456 set into Charlie.
Here is the log from running these actions:

Advanced Uses
For those of you familiar with Groovy, this feature uses the Groovy method:
tokenize(String Delimiter)[Number Index]
Care must be taken to be sure that Index is in bounds. Were we to ask for index 3 for the string used above, the rule would throw an index-out-of-range error. There is no protection against such an error, it will crash your rule.
One advanced use of this feature is to pass multiple parameters into a rule from an endpoint trigger that sets a String Global Variable. Then the rule actions could take apart the passed in string into its token elements, and use those in a Custom Action to perform some task.
The example below shows a rule that uses this to set a lock code on a lock. Notice this rule uses another new feature to set a Number Variable from a String Variable that contains a numeric string.

Here is the URL for the endpoint:
This endpoint would create a lock code on the Garage Lock in slot number 6, code of 9876, and named "New Code".



