I had a "disaster" at one of my clients in the last few days.
Unfortunately, they didn't inform me that something was wrong until 3-4 days had passed, and in that time Hubitat lost contact with 14 leak sensors! (needless to say, rejoining 14 sensors is not how I want to spend my time...).
I assume that the cause was a lack of free memory, because:
the situation "calmed down" (to be explained later) after I rebooted
all of those sensors were lost at approximately the same time
what does "clamed down" mean?
the following screenshot from the logs, shows how Hubitat is not calm:
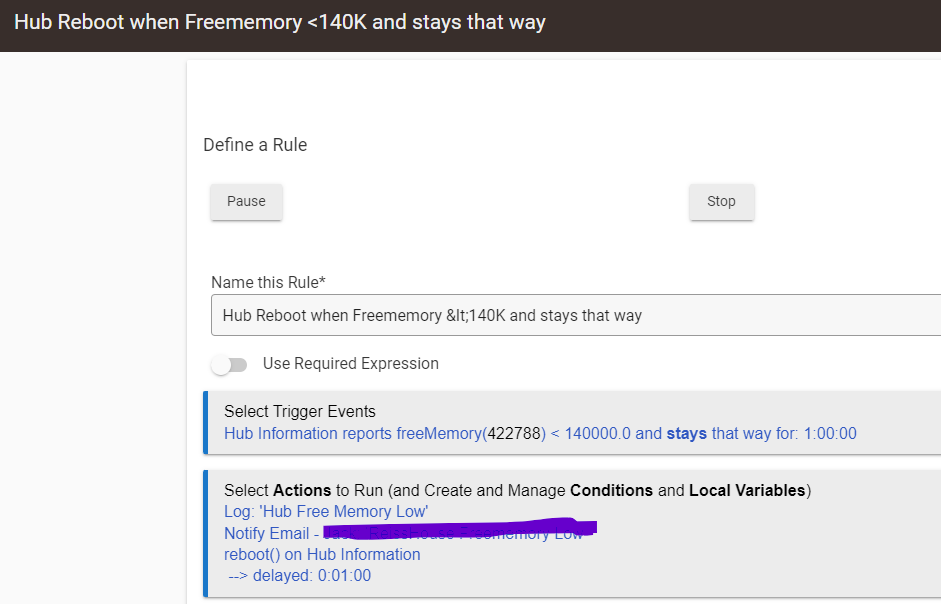
I believe there is a SevereLoad location event that you could check for in a rule.
Not sure if that's the correct application of this test here.
Probably have to also get down to the root cause.
I'd also add, 140Mb does seem a little low... it may be worth setting up some monitoring of system metrics like this so you can look at trends over time. Unless you have done this already.
I personally have these exported to Influx DB and charted by Grafana, so can chart them over time, but there are other options if you don't have an Influx / Grafana setup. There can be plenty of discussion about what may or may not be the best metric to use in order to understand the health of a system such as HE. I don't claim to have the answer, but prefer to capture details like these so I can review them on a semi-regular basis or if an issue comes up. Better to have information than not. As long as you analyse the results with an open mind and a willingness to accept different interpretations to those you may draw yourself.
Basically, capture whatever you can. without bogging down your hub(s) too much, so that you can troubleshoot when necessary. All of this is dependent on what options you have available to you (or your clients), so alternate options to Influx and Grafana may be worth pursuing.