
I know it is in beta, Chromecast device, What am I missing. Seems like no matter where the request is from, the device should report correctly.. i am idle, i am speaking, i am off line?
The above 3 lines of RM just do not seem to work.
another "what am I doing wrong? episode...
What isn't working? I see that it's currently idle. The "Wait for Events" action will wait until the device again reports idle, meaning it would need to change to something else in between. If you don't want that, "Wait for Condition" will proceed even if it is currently idle. But again, it's not clear what you believe is a problem.
If the device is currently speaking (presumed not idle) the next RM (or portion thereof) with this "talks" over the currently being said line. There appears to be no change in the status that is being determined by the next RM rule or portion of a rule. The 3 lines above are in a state that should allow the rule to proceede, but when it is activly speeking, the rule will not pause and the wait is effectivly skipped.
You're presuming that the device is able to update the status of the speaker in the short time that a TTS announcement is playing. The only way that that updates is to query the Chromecast device. So, I would confirm on the Edit Device page that the status of the speaker actually changes away from Idle when you issue a TTS announcement to the speaker.
I have cought it in the not idle mode. I am presuming that if a TTS message is currently using the device, that it is not idle.When it is done, it is idle. the rule can proceede to TTS.
Okay....can you show a log of your rule when that happens?
You have to show us the entire rule. A rule requires a trigger as well as other actions. So, show us the whole rule and we can see what's going on.
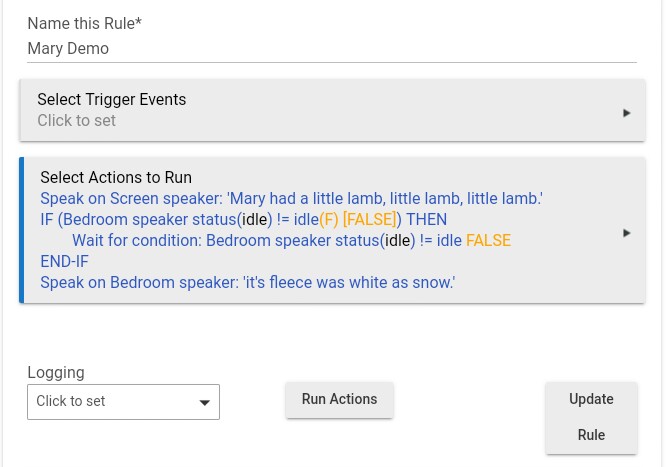
An easy one to re-create.
Numerous attempts at getting this to work. I do understand how this works. Just not why this does not work. It seems so simple. Push "run Actions" and it talks over itself.
okay...show us the logs for the device where the status was updated to something other than idle.
You do realize that the If part is going to be executed before the speaker actually starts talking right? There is a significant delay for the speech to begin, the rest of the rule would have already been executed by that point.
It can't talk over itself. You can only cast one thing to the speaker at a time. The second will interrupt the first.
That's different from what you have above: the Wait is for != idle here but = idle above, and you used "Wait for condition" rather than "Wait for event". I'm assuming you want it as you had it originally or as a hybrid of the two, not as created here, or at least that would make more sense to me. That aside, what you need to do in either case, as suggested, is verify that the status attribute on your Chromecast device changes when you expect it to (I don't use this integration, but if it does indeed rely on polling, it certainly won't be instant and possibly won't be fast enough to use as you intend here).
If that's the case, in rules like this you could work around the problem by concatenating everything you want to say into one string, then speaking that last. Perhaps you can think of other ways to approach this as well.
Even if it were correct, it would still not work. The whole rule is going to execute before the message is event sent to the speaker meaning there is no time for the speaker to move off of Idle. The if part of the rule will be false. It will still be idle, so the IF part will not pass, so the wait will be skipped. Then the second TTS will happen.
Put the second TTS inside the End-IF. I bet you never hear it.
I would like to just drop this subject. I am willing to wait for the beta to mature.
I can get to trunincate, talk over and do about anything I want it to except concantinate and TTS.
Sorry for the disturbance.
Don't give up!  If you can get what you want concatenated into one string variable (sounds like you know how to do that?) then speak it all at once instead of trying to spread it out into different chunks while waiting for "idle" status in between, that's likely to work a lot better.
If you can get what you want concatenated into one string variable (sounds like you know how to do that?) then speak it all at once instead of trying to spread it out into different chunks while waiting for "idle" status in between, that's likely to work a lot better.
I wouldn't hold your breath waiting for the Chomecast integration to mature--I'm not sure it's changed much, if at all, since its introduction. Might as well do what you can today, and you'll also get something that would be usuable with other speakers that don't necessarily report this status.
1 Like
Where I give up is that I hope to see the device as a device. Usable across Rules and Hubs. There are work arounds. Delays and such. Easier to just allow the rules to run as they seem fit. I do not know it that explaines it properly. It is all I have.
This technique would be usable across any rule. I'm not sure what you mean with "hubs"; if you expose a device via Hub Link or HubConnect, the same would apply. The "status" attribute is not part of Hubitat's Speech Synthesis capability you're using this device for. Devices can implement custom capabilities, and perhaps this is one, though since the device can also do music, perhaps it is using that attribute from the MuiscPlayer capability. However, the possible values are apparently not defined (and not required for speech only; I don't see anything that would require the device to report differently if it's currently speaking), so I wouldn't count on this working across devices, just maybe with this specific one if it were ever implemented exactly as you desire. I'm not sure I'd count on that--or on its reliability, or at least speed, if it's polling-only.
To clearly illustrate what I said in my previous post: all you'd have to do is store the whole string in a variable, then speak the string all at once instead of pieces. Since you haven't shared what your actual rule is doing, I'm not exactly sure what to suggest. However, here's an example of where I've done this myself:

All you have to do is set the value of your string variable to the previous value plus whatever extra text you want (that is what I'm doing in my second and third IFs). In addition, you have to define a local (or global, I guess) variable to use:

I'm not sure I'd consider this a "workaround." This would probably be my preferred method of speaking regardless of what my device supports (and mine is super-unofficial and definitely does not support this; my official Sonos device does, but I'm playing music on it right now and it insists it's "paused," so I'm really not sure what this attribute is supposed to do in general). The fewer command sent out by the hub to devices with just a tad more work on the hub, the better, in my opinion.
The problem is not the platform, it's that you expectations are unrealistic. The integration is not going to "mature" to the point where it will update instantaneously. There are other ways you could get this to work but since you don't seem interested in hearing them, I won't share them with you. Good day.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed.

