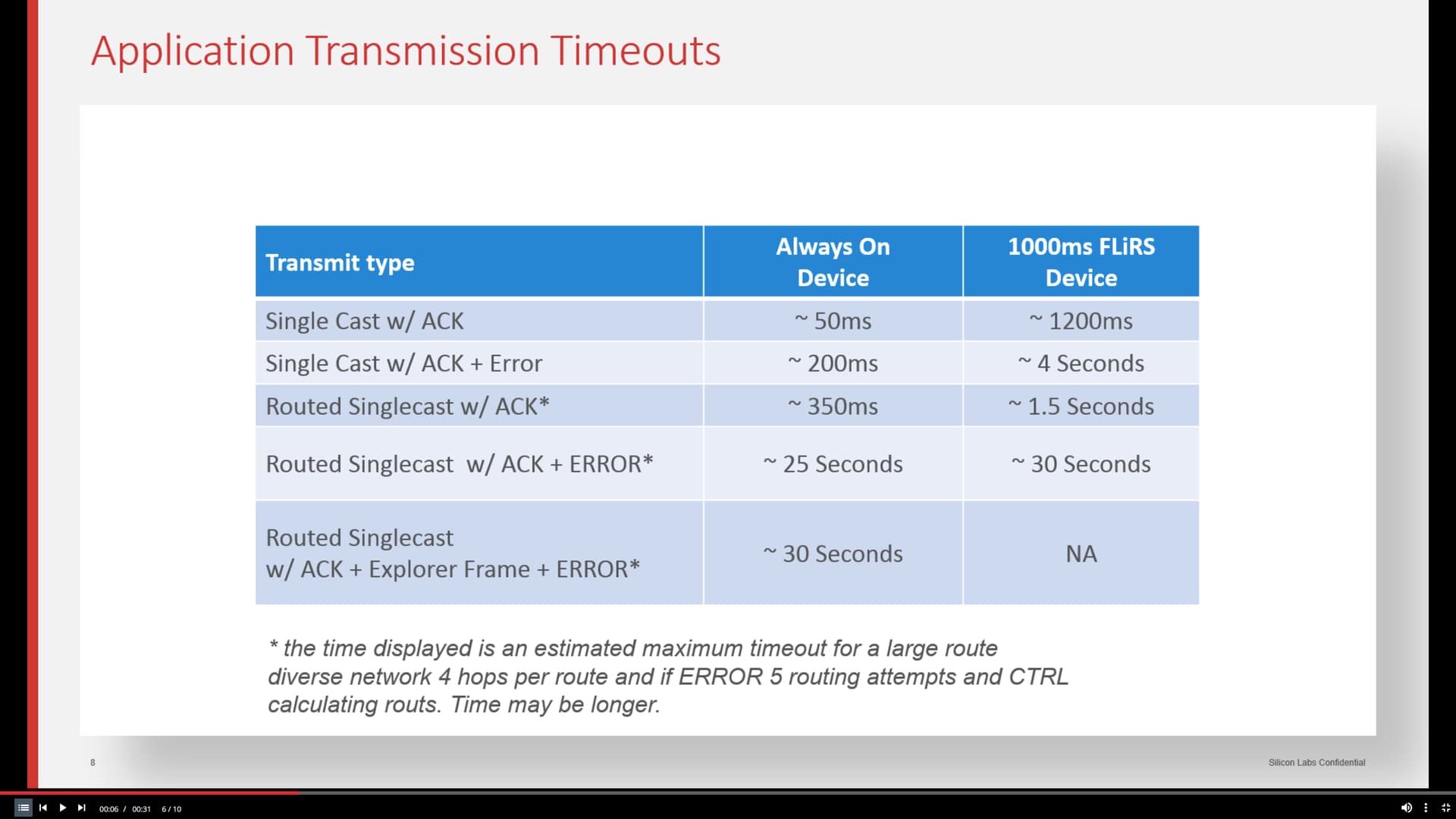
Z-Wave routing uses singlecast w/ACK, routed singlecast w/ACK, and (in the case of route failures) explorer frames; each has an expected max timeout at the application level. In their Z-Wave routing tutorial, SiLabs shows typical application tranmission timeouts (for a 'large route diverse network') in the table below. Note that 25 second delays are possible and symptomatic of multiple retry attempts of a series of stored working routes. Tack on another few seconds for the explorer frame fallback and you get to the 30 second delays you're evidently experiencing.
The short video tutorials are worth watching to understand why the 25-30 second delays are possible.
Unfortunately knowing the 'why' doesn't lead to knowing 'how to fix'. Once you've followed the best practices you've got to rely on the protocol to do its job; a lot of stars have to align for things to work efficiently,
In a perfect Z-Wave world, the controller has an accurate inventory of all Z-Wave nodes and current knowledge their in-range neighbors. It must also update that inventory (via neighbor discovery/report at inclusion or repair) every time a node is included or excluded, if the nodes get moved, or the RF environment changes significantly. If calculated/distributed routes aren't 'correct', they'll be used, retried, and fail in succession leading to the explorer frame fallback and excessive response times.
The nodes themselves must accurately report their neighbors, have sufficient memory to store a table of last working routes (otherwise they'll need to be repeatedly re-discovered) and keep those tables up to date.
When listening to the tutorials (linked here: Z-Wave Mesh Performance
--videos 8 and 13 are the most informative) I got the impression that only devices based on newer SDK's (4.5 and 6.X) are capable of doing this; even so, as network size increases the expected retry timeouts make this scheme delay prone unless transmissions always are error free.
Throw the 700-series apparent teething problems into the mix and there's really not much an end user can do about it, other than subdivide a large mesh into a couple (or more) smaller ones-- that would effectively reduce the maximum expected timeouts by reducing hop count and route complexity. The fact that so many routes are showing 'direct' yet the response times you're seeing reflect routing failure/retry timeouts sure looks like there's a mismatch between the controller's view of the mesh and reality. Maybe that's at the root of the problems to be addressed by the expected firmware fixes.

