Thank you for your help and attention. It's very cool that Hubitat has this forum and that people are so willing to help.
Point taken: I've enabled action logging, and I'll stop spamming the list with my partial logs!
RM coding style aside, something else must be going on here. However verbose or unorthodox my rules are, the flow of that particular jump from the first rule to the lights-off rule seems easy enough to reason about that I expected to see at least one off event in the logs (action logging wasn't enabled, but event logging was, and it should have reached at least one lights-off action).
I'll be more helpful if it happens again.
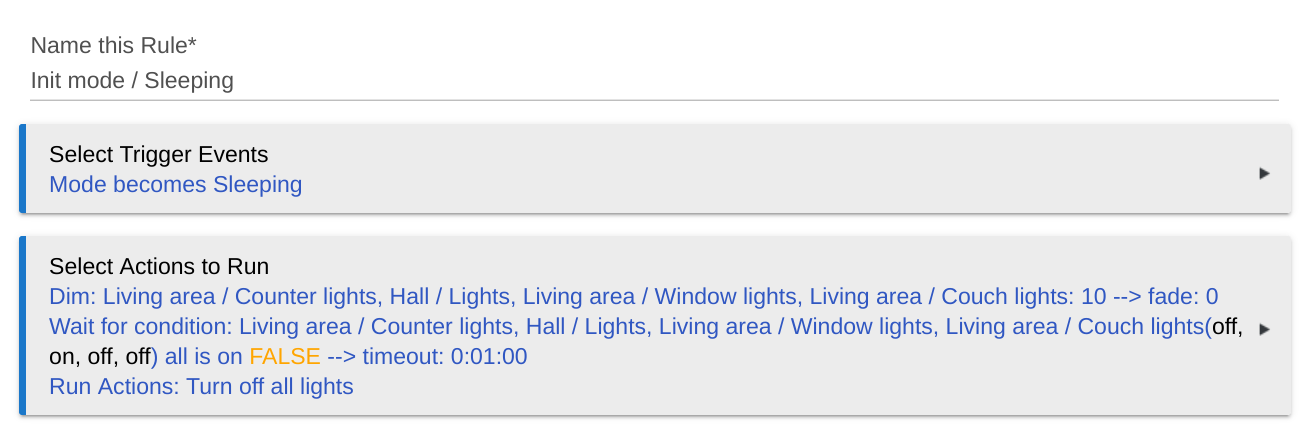
I still defend my wait and wait timeout, and, by the same token, at least pieces of the verbose lights-off rule.
Wait: As far as I can tell, when the switches receive the off command at least (or are turned off physically), they fade all the way down before they send the "I'm off" state change (even the LED on the switch doesn't indicate it's off until then). Even if they ACK that they received the command (I don't know the Z-Wave protocol), the state doesn't seem to change synchronously, so any later actions that assume they're already on (such as turning them back off), had better make sure these actions "take" in the right order. It's the idiom I've adopted to turn async requests into sync requests. I was bitten by it several times in multiple rules before I discovered this race between components. (GE 2nd gen dimmers, in case that matters.)
As for the timeout: I would never issue a synchronous RPC without a timeout, especially if it went over the air or touched other systems. Here, I don't know anything about the Hubitat stack or hardware, the drivers, the Z-Wave protocol itself, or the Jasco hardware or firmware. I do know that every switch must have to ack that it has been turned on before the wait condition could possibly be satisfied. If one switch misbehaves (or is just unreachable) and prevents getting passed the wait, it'll hang indefinitely. The timeout seems like a cheap and straightforward way to gain some failure isolation in the one place I have control.
I have, in fact, observed Hubitat reporting the wrong state for a switch (quite possibly because of the switch). I'm fine with that because it's as rare as it is inevitable (the only variable being the actual failure rate). But this error compounds with more switches that a single action relies on, maybe doubly so if Z-Wave interferes with itself or floods the Hubitat with updates. I haven't found documentation on this, but I have anecdotal evidence that flipping many switches at once is less reliable than flipping one. Writing rules defensively seems like the responsible thing to do because this is a complex networked system.
The other relevant angle is that I really don't care about the 10%--it's a nice-to-have--but I do really want the lights to turn off, and some off is better than none. So even a small possibility of dislodging from a hung wait is probably worth it.
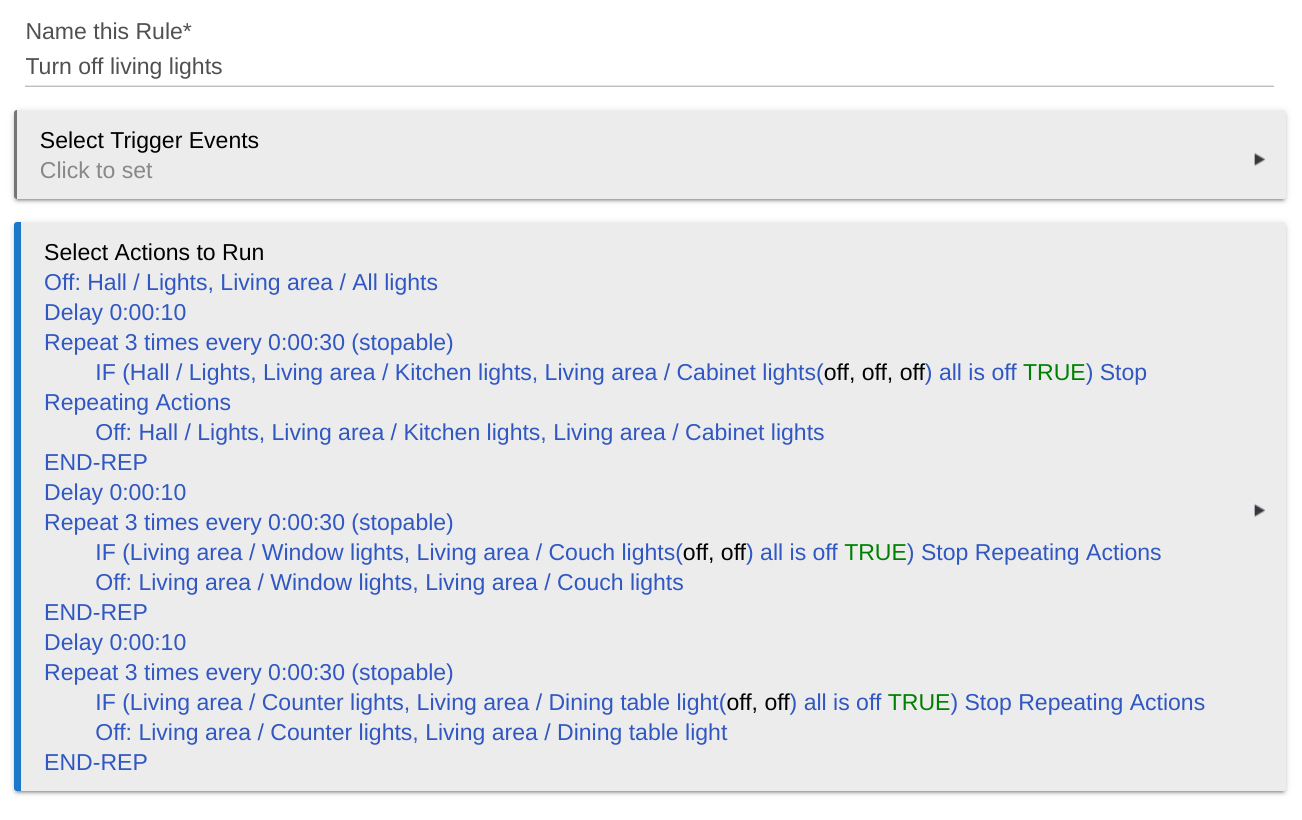
This philosophy applies to the nasty repeats as well. I totally agree it's ugly, and this is the only place I do anything like that because it's the only place I absolutely, for sure want to make sure the lights go off because I'm not there to observe them (and may not even be home).
In addition to the very occasional no-ACK scenario above (with compounding error), every now and then the Hubitat gets a little slower to respond to events, then it recovers. It's rare and not a huge deal at all, but it adds transient issues to the list of things I should design around (again, only in these "critical sections") by backing off and trying again later if something doesn't work. So, given that it could help in this one critical place as long as I can reason through my rule and iterate fixing any bugs, it seems like a reasonable trade-off.
I should point out that I'm not talking about huge errors rates here by any means, but enough that I'd like to address it. The lights have only still been on in the morning once since I added the extra loops ~50 days ago. But if I wake up more than, say, one morning per year and the lights are still on, that's outside my tolerance, and that could seemingly happen with a very, very small per-switch flip error rate.
So while I agree that there very well could be a bigger problem elsewhere, no networked system is perfect, and it seems that as long as I carefully audit that one rule (treat it like a critical section), it can only help isolate and work around certain kinds of failures.
Yes, I "call" that lights-off rule and, independently, its living lights off helper rule from elsewhere. I use it for various many-lights-off scenarios where it's okay for it to be slow and methodical (e.g., when I'm asleep or away).