Turns out I wasn't patient enough to wait for a reply so I kept experimenting and got it working. Here is my version updated from yours, but working for me:
Here is the complete (I think) list of changes and the reasons:
Removed "cd [DIRECTORY_OF_YOUR_BACKUPS]" because I put the directory into the commands themselves.
Updated "cookiefile=`/bin/mktemp`" because the wrong single-quote was used.
Added "backupdir='dir'" to avoid having to retype it repeatedly.
Added "cookiefilename='cookiefile'" so I could combine it with the backupdir to leave cookiefile as is in later commands.
Removed " -X POST " because this seemed to be returning a 405 error from the Hubitat.
Replaced "xargs -I @ curl -o @ http://$he_ipaddr/hub/backupDB?fileName=@" with "xargs -I @ curl -k -sb $cookiefile https://$he_ipaddr/hub//backupDB?fileName=@ -o $backupdir@". I did this as the -k was needed to not run into error with the hubitats SSL certificate and is -sb $cookiefile was needed to use the cookie to prove login and finally added the directory to the output rather than depend on the cd that was removed.
Net-net, here is a version of my new version with actual (but made up details):
Finally, I am trying to decide if I want the backup to have the name that was on the HE (actual date data gathered) or if I want the time date I backed it up to my computer. To do the latter, I can change the last line of the script to:
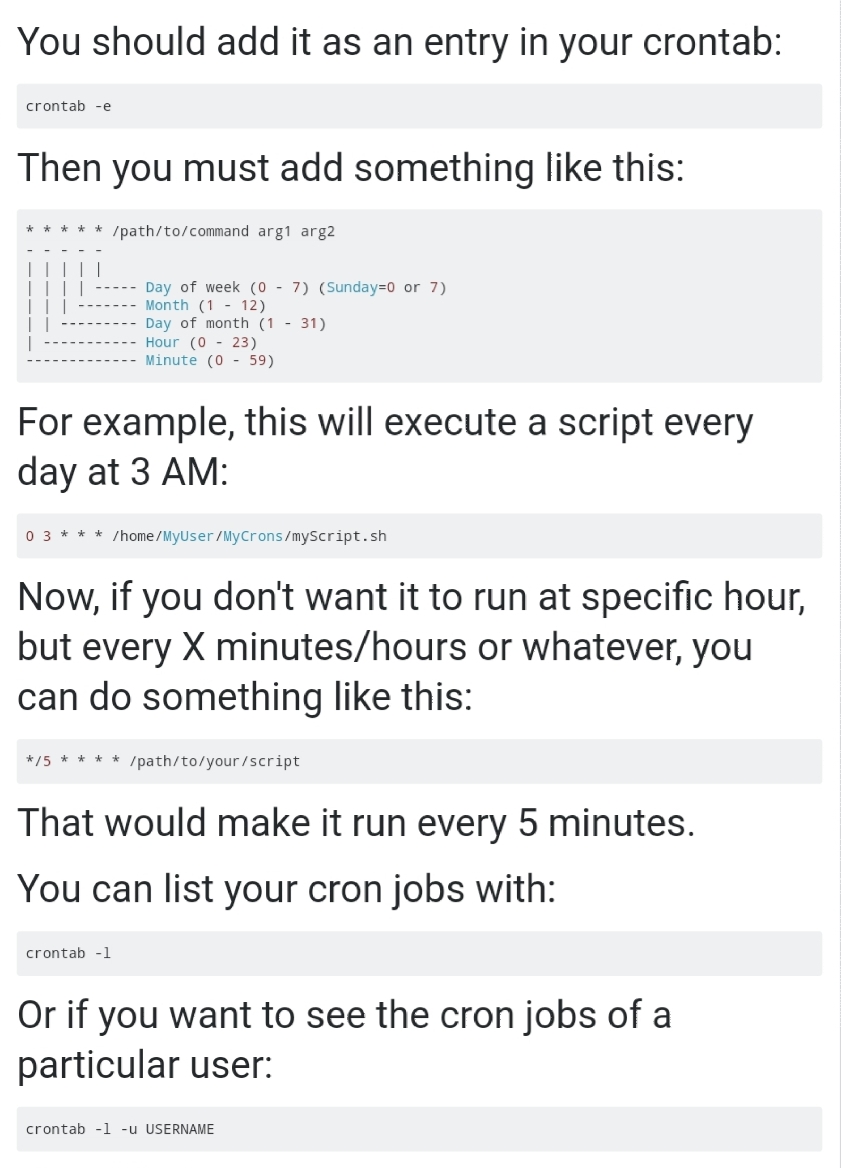
Unfortunately your next question is beyond my knowledge. I am just planning to run this manually whenever I want to. The reason I want to do it via script is that I have 4 different HE in 2 different locations. Thus my plan is to expand the script to cover all 4, then run it before I go into each of them to make changes like updating firmware or updating key drivers etc.
Good Luck in finding a way to use crontab or other methods to trigger the script on the schedule that works for you.
Hubitat recently added optional subscription services, one of which includes the ability to save hub backups to the cloud.
This thread has been discussing local, LAN backups (previously the only kind of backup that existed).
It’s entirely possible something changed that makes some user scripts to retrieve backups from the hub over the LAN no longer work as written. I don’t actually use one at the moment, so im not sure.
But I don’t see why one would jump to the conclusion that they are surreptitiously trying to disable previously functional features in an effort to “force” users to sign up for new, optional, cloud-based services.
All while they’ve publicly stated repeatedly that they have no intention of removing access to features that previously existed, just adding on and improving new features for those users that want to pay for them.
Mine (happily stolen from someone else smarter than me, but can't remember who) is still working on my Synology NAS:
On Synology NAS scheduler:
Task 1, Daily: Copy backup file from Hub to NAS:
cd "/path where you want to store backups"; /usr/bin/wget http:///hub/backupDB?fileName=latest --backups=14 --quiet
Set "--backups=14" to the number of backups you want to keep before removing older ones. I save two weeks worth before starting to drop off older ones.
Task 2, Weekly: Creates a copy of the current backup once a week and saves it - these are not automatically removed - they are kept until I manually delete them.
cd "/path where you are storing backups"; /bin/cp backupDB?fileName=latest hubitat_$(date +%Y%m%d).lzf
Would I be right in thinking that one of the differences in your script is that it is downloading the latest backup file already captured by the HE hub automatically, whereas the other methods listed are requesting the HE hub to perform a fresh backup at the time the HTTP calls are made, then downloading that file?