Event / States will truncate at boot up and approximately every hour. Their growth affects the database size, but except for the memory consumed/returned during the write should have little to no impact on freememory.
3 Likes
Let me monitor that and see. I know initially, using the UI to set the limits didn't apply to that motion sensor, but using the web address did.
This might be considered an edge case but it is a valid case and will do as I suggested. If freeMemory drops to or below 300,000 at 4:49 AM and stays there until the hub is rebooted.
@4:49 AM the rule is triggered and the ELSE-IF condition is True. Reboot is scheduled for 5:01.
@4:54 AM the rule is triggered and the ELSE-IF condition is True. Reboot is scheduled for 5:06.
@4:59 AM the rule is triggered and the ELSE-IF condition is True. Reboot is scheduled for 5:11.
@5:01 AM the hub reboots and freeMemory should now be well above 300,000.
The rule is now outside of the Required Expression and won't retrigger and since it won't retrigger the Cancel Timed Actions won't be run so the hub will reboot at 5:06 and 5:11.
You posted that you update the Required Expression and Trigger Events. If you didn't change the IF-THEN logic too then there won't be anything to run the Canceled Timed Actions within your time frame and you'll always get multiple reboots.
1 Like
Ok, watched it, and that is correct. Top of the hour, it consolidated states at brought them back to the limits.
Question about the "states limit". I have it sent to a global "20". The ones I looked at, had only 1 attribute, and reset to 20.
If have a device that has 10 attribute/state variables, and a 20 limit, should I see it wrap at 200 then?
Answering my own question here. If a device that has 10 attribute/state variables, and a 20 limit, will wrap at (10 x 20) = 200 on the hourly cleanup boundary, and left events at 20 so I cab grab history from the log.
I ended up setting all devices to wrap at "1" state per attribute. I have no use for those states as history, which seems to be what's "rotting" my hub over time as they build up. I'll monitor it over the next couple of days to see if RAM was the root of my slow down or if it's something else.
Sure:
IF (Hub Information freeMemory(330620) > 300000.0(T) [TRUE]) THEN
Cancel Timed Actions: **This Rule**
Exit Rule
ELSE-IF (Hub Information freeMemory(330620) <= 300000.0(F) [FALSE]) THEN
Notify Derek's iPhone - HE, Email Notifier: 'Low memory detected, Rebooting Primary Hub' --> delayed: 0:11:30(cancelable)
reboot() on Hubitat Controller --> delayed: 0:12:00(cancelable)
END-IF
And here’s the JSON
2 Likes
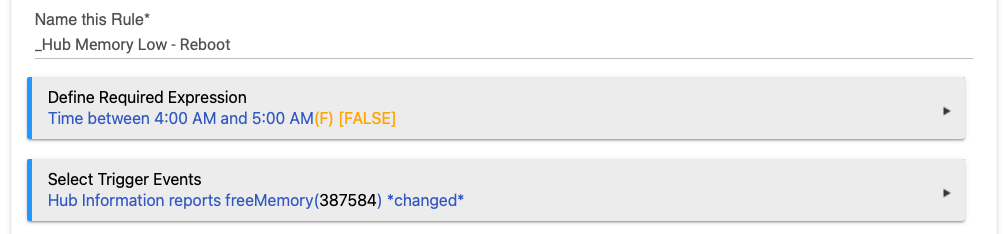
@dJOS The comment you quoted was in regards to the updated Required Expression and Trigger that you posted today and the trigger not satisfying the first part of the IF-THEN logic. It won't show in your logs until the next time the rule runs and reboots your hub. Your hub, your rule, good luck!
I think you misunderstand the rule. It won’t even enable the trigger logic unless it’s between 4-5am.
And then the trigger condition is only going to be tested every 5 mins when the hub information driver polls and updates the free ram.
OK, so the 2.3.0.121 or 2.3.0.124 versions (for sure, only ones I've really did the deep dive) have a perpetual memory loss and slow down. To @dJOS point, as soon as my hub gets below 300k as well, the slowdowns become humanly noticeable. From what I tracked previously, it's a linear slow/day effect. Once the memory drops way too far, I lose my Zigbee, the logs show that the Zigbee was disabled and re-enabled.
I had dropped all my events/states to see if that made a difference. It did reduce my DB size as expected, and the RAM swing from an hourly state/event cleanup to the next hour did reduce, but I'm still leaking RAM. Below is a screenshot of all my app states/events/state sizes. The green row was bootup. I was doing some cleanup, and deleted 3 apps (next row). I had lost 120k RAM, while having large reductions of states/events/state sizes (so this isn't related to them). Manually ran the DB cleanup, had further RAM loss, while removing more states/events.
Bottom row is a full 24 hours since reboot. I'm down to 308k of RAM, with zero correlation of that loss to my state sizes, states and events.

1 Like
I am seeing similar slow downs and memory reduction over time as well. Just setup a reboot RM rule to fire if freemem drops below 300k as others have suggested. I hope the dev's are watching this thread and isolate the problem. It's fairly clear from my graphs and what others have shared that there is some sort of memory leak going on.
Edit: forgot to mention this is on my C7 hub. I haven’t look at this on my C5 yet.

2 Likes
The memory leak is present on the C5 as well. I can get away with rebooting at 200K. That gives me an average of 8 days between reboots. At the 300K threshold I would be rebooting daily.
Can you correlate anything or any device activity with the occasional sharp drops shown in your graph?
1 Like
Unfortunately no, After I reboot I see similar patterns as the previous period no matter the time of day or device activity.
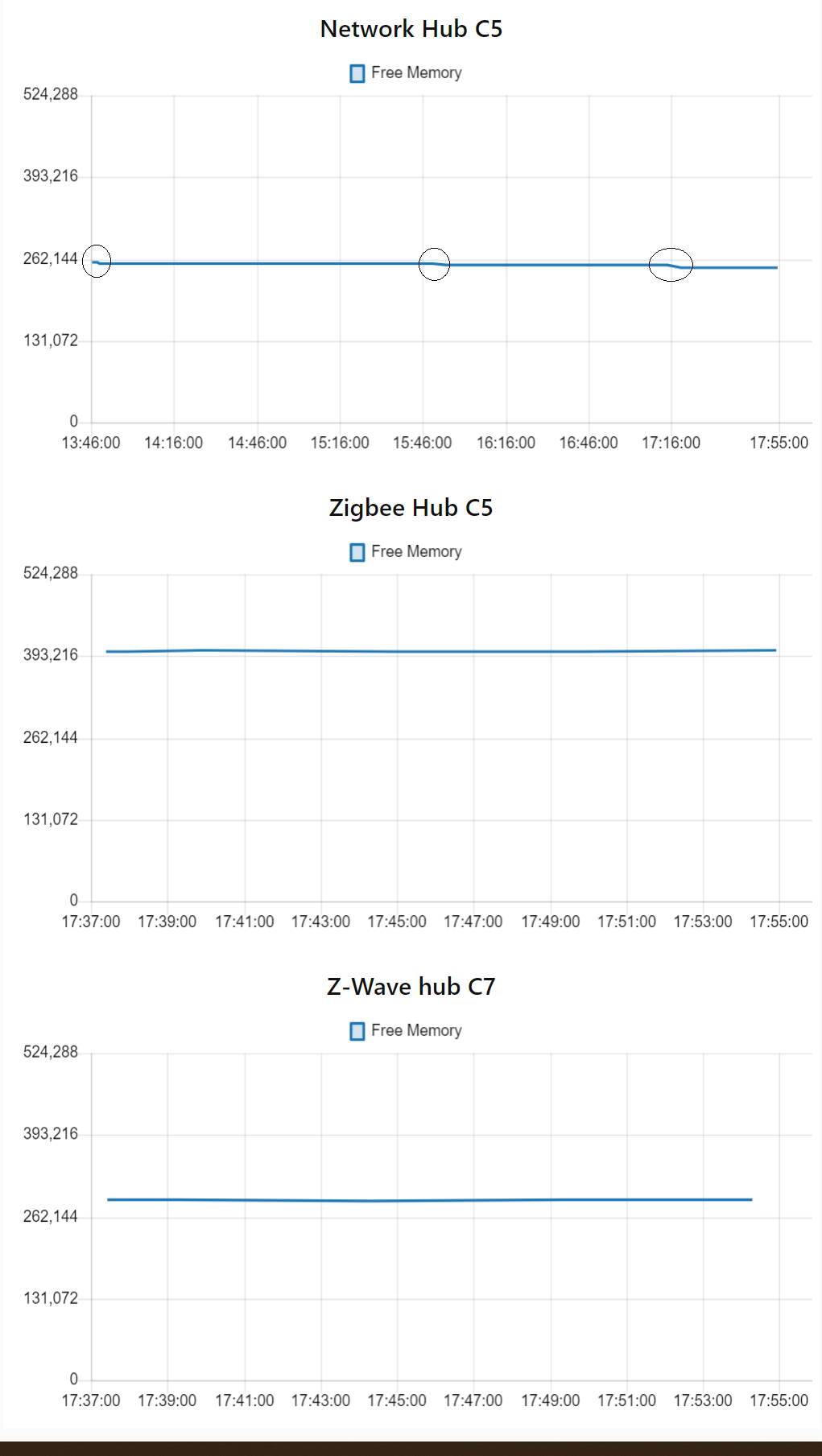
So thanks to @tsviper started some simple HubInfo monitoring of my 3 hubs - C7 Z-Wave, C5 - Zigbee, and C5 Cloud/Network apps. Nothing fancy just free memory data straight to a chart node, not retaining anything for now. On my cloud/network hub memory seems to be declining.
On that hub I have no rules and the following apps/devices:
- Lutron
- Alexa
- Homebridge
- Flume
- Maker (4 instances)
- Groups and Scenes (just removed)
- HPM
- HubInfo
- Roku Connect (just removed)
- Lift Off driver
My C5 & C7 seem to be okay but haven't been monitoring long enough to say for certain. These hubs are split out by function so will be interesting to see how that impacts things..
Sorry dude, you were right! ![]()

I've now changed the Trigger back to *changed* so that way the rule will self cancel after the reboot.
where is the reboot command in rule machine
It doesn't exist - we use either the "Hub Information" driver reboot command (IIRC it's an Actuator) or the "Hubitat Hub Controller" driver (it's an Actuator).
1 Like


