Not yet. I will be updating this week to allow multiple selections. I have multiple Samsung Multirooms, so will test against those. Standby. (Note: There are some concerns with the speaker trying to resume a playing tring between messages interfering with the messages themselves (happens on Samsung). I am including a user-selected delay to allow fine tuning. That is the current delay.
1 Like
Single Speaker complete. I have completed the single-speaker application for TTS Queueing. Some notes:
- the refresh is specific to the exact speaker, so some user tuning is provided through the preference "Delay between buffered messages in seconds"
- Commands are also available to test the various audio notification and voice synthesis commands against your speaker (Volume,
- ClearQueue is available for testing and to clear.
- TestQueue sends four pre-programmed messages at different messages. This will allow you to fine-tune the speaker-specific resume functions that (on the Samsung Speakers) are somewhat quirky). Some times the recovery function truncates the next message. I needed a 15 second buffer to assure all of my channels could recover.
- The delay also allows you to interpret one message before the next one plays.
- Finally, the multiple speaker version of the Application should be out this week.
Location:
2 Likes
Dave,
This looks really useful. Do I understand that, when you have the multispeaker version, I can create a virtual device that controls a speaker (one virtual device per speaker) and will queue speak commands from any TTS app, e.g. RM, Message Central? I have various Google Homes/Minis, Echoes/Dots, Insignia GH's, your Samsung WAM driver, Eufy dots - will all these work?
Thanks for your work!
Tried installing the current version posted on your GitHub, but I'm finding that the install screen doesn't give me the option to select the virtual TTS device only the real speaker?
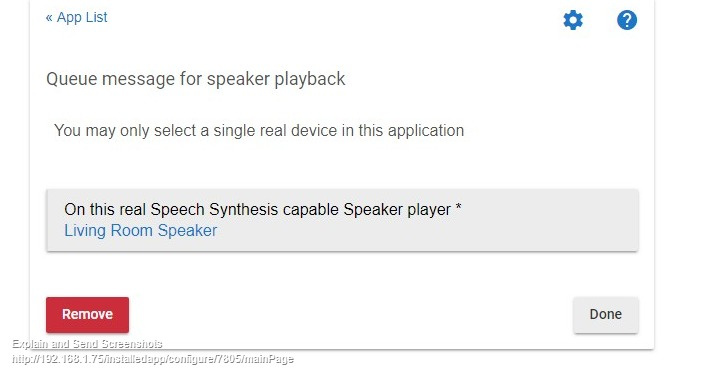
Edit: Disregard figured it out
1 Like
@djgutheinz Dave, seeing some errors when trying out this app/driver with my Sonos speakers:
Device Error (Sonos):
dev:47232019-03-05 09:39:37.045 am errorgroovy.lang.MissingMethodException: No signature of method: sonosDriver.playText() is applicable for argument types: (java.lang.String, java.lang.String) values: [This is a test of Audio Notification Buffering try two, 44] Possible solutions: playText(java.lang.String), playText(java.lang.String, java.lang.Integer), play(), playTrack(java.lang.String), playTrack(java.lang.String, java.lang.Object) on line 152 (playText)
App Error (TTS Queueing)
app:78142019-03-05 09:40:03.348 am errorjava.lang.IllegalArgumentException: Command 'playTextAndResume' is not supported by device. on line 64 (playTTS)
app:78142019-03-05 09:40:03.323 am debugplayTTS: playint: This is a test of Audio Notification Buffering try four. All done., volume = null, method = playTextAndResume
app:78142019-03-05 09:39:50.086 am debugplayTTS: playint: This is a test of Audio Notification Buffering try three, volume = 33, method = playTextAndRestore
Speaker appears to playback every other track of the test (try one, try three).
Hope this helps track down issue.
The test is against the "capability audio" notification and capability speech synthesis.
SONOS vs AudioNotification and SpeechSynthesis
Comparing this to the current, stock, SONOS Speaker driver (command by command):
playText YES
playTextAndRestore YES
playTextAndResume NONONONONO
playTrack YES
playTrackAndRestore YES
playTrackAndResume NONONONONO
speak YES
What I am surprised about is the playText (it wants a string, I sent a string)?? Will modify in final version.
1 Like
I have made the decision to use the Speech Synthesis capability only for the buffer. That will reduce the command to SPEAK. I will also change the SPEAK to toString prior to sending back to the driver.
Dave
1 Like
Looking forward to the multi-speaker version! Really liking not having announcements cancel each other. I'm actually quite surprised this type functionality isn't part of the built-in driver @mike.maxwell has done this with the chromecast integration so I'm assuming it could be done in Sonos too?
Multi-Speaker TTS Buffering App and Driver
The multi-speaker TTS Buffering app and driver are complete and may be found at:
Features:
a. Creates a virtual speaker for use in rule-machine that will buffer the notification text to avoid one text overwriting another.
b. Includes variable delay to allow changing delay between message to (1) allow you to comprehend the previous message and (2) allow your speaker to recover playing audio (if supported).
Issues:
a. Tested on Samsung WAM 1500 (R1) speaker using the Samsung WiFi Audio Driver).
Installation and Update: See README.md on GitHub.
NOTE FOR SAMSUNG MULTIROOM USERS:
I am working on adding this internally to the Samsung Multiroom driver so that this will not be necessary. It will take a week or so to get it completed.
Dave
Tried this version, lots of errors in log, and no output to real speaker (sonos)
app:78152019-03-05 12:58:12.945 pm errorjava.lang.NullPointerException: Cannot invoke method speak() on null object on line 54 (playTTS)
Edit: Any thoughts on what is causing this error? Happens every time I try to "speak" a message from one of my virtual TTS devices. Wasn't an issue in prior version.
Did you run the application and do a done after updating?
Go to the device's page. In the data section (near bottom) is Device Details. One of the data elements should be
"realSpeaker:"
with the label of your real speaker.
I installed new code from scratch and re-installed app when you released multi-speaker version. Device data excerpt is attached, ton's of stuff:

Yes. That is the error. Fixing NOW. (do not know why it did not come up in my testing?) Will update code tomorrow AM after I can retest.
1 Like
Just updated app on GitHub. Tested.
Replace code in APP only. Run App and select done. This will update the data section of the device. (tested this way).
After that, you will see in the device data something like:
"realSpeaker: Speaker Left"
Not a lot of other data (which is the speaker's data within the app).
I want to know if it works.
Yep, errors are gone, and audio is playing correctly! Thanks!
Pleasure working with you. Any concerns or problems, I will happily try to address.
Dave
Experimenting with buffering delay, it seems I can set it REALLY low with my sonos, down to 2 seconds and it still completes without a problem.
I've installed this on one of my Sonos speakers (great job, btw), and can't seem to get it to resume the previously playing track. Is this not possible?
Edit: @djgutheinz does this mean no resume with Sonos?
@djgutheinz Having issues with the App and Driver.  I have errors and nothing announces on the Samsung M3.
I have errors and nothing announces on the Samsung M3.
Issues:
-
When loading the app it defaults to my Samsung M3. BUT if choose to see other choices the Samsung M3 really isn't there. See image below:
-
After using the default Samsung M3 and allowing app to create TTS App Logs device I get the following errors in the logs:
app:18042019-03-06 08:36:03.620 am errorjava.lang.IllegalArgumentException: Command 'speak' is not supported by device. on line 54 (playTTS)app:18042019-03-06 08:36:03.599 am debugplayTTS: playint: This is a test of Audio Notification Buffering try four. All done., volume = null, method = null, realSpeaker = Samsung M3
-
Here is the logs for the Samsung M3 TTS Queue device
[dev:1936](http://10.0.2.38/logs#dev1936)2019-03-06 08:25:44.258 am [debug](http://10.0.2.38/device/edit/1936)Samsung M3 TTS Queue 0.5.05: processQueue: TTSQueue = [[This is a test of Audio Notification Buffering try three, 8], [This is a test of Audio Notification Buffering try four. All done., 9], [This is a test of Audio Notification Buffering try one, 8], [This is a test of Audio Notification Buffering try two, 8], [This is a test of Audio Notification Buffering try three, 8], [This is a test of Audio Notification Buffering try four. All done., 9]]
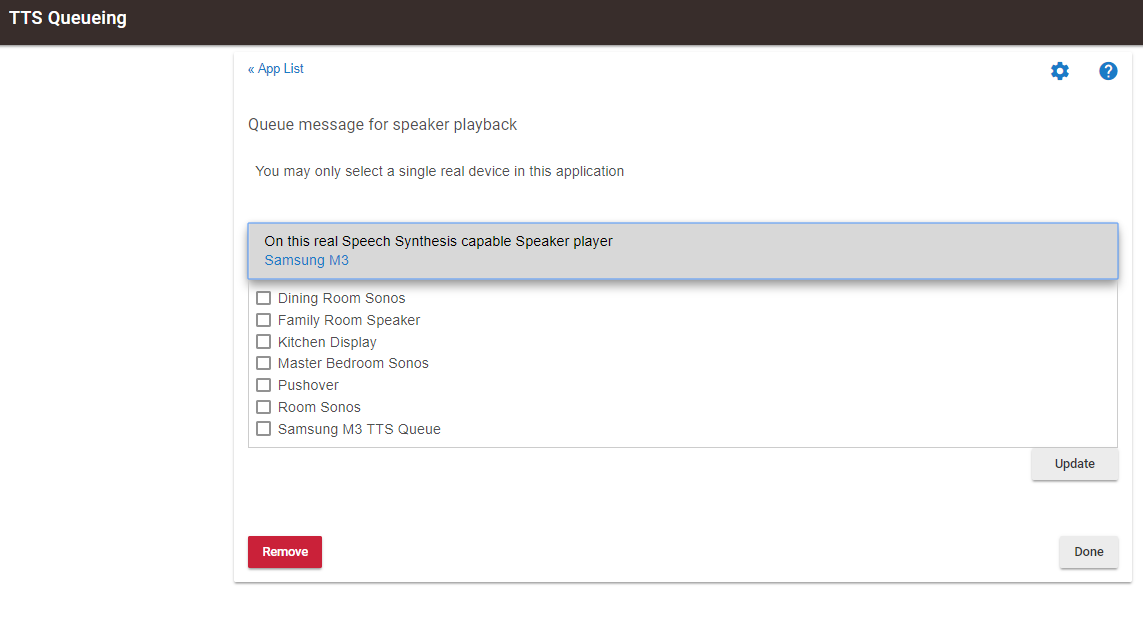
Am I doing something wrong?
I will place updated driver on GitHub this morning (about 1 hour).
Just updated. This added the capability "Speech Synthesis" which is what is used for the text notification.
Note: Within a week, I will be updating again to integrate the notification into the driver itself. This will solve a problem with the recovery functions within the speakers (that I can not solve on an external item).
Dave

