With all of the incredible community integrations of devices and apps; Echo Speaks, Message Central, Big Talker, Welcome Home, etc... do you all think there is a need for a TTS Queue controller?
My reason for this:
Someone comes home and opens the front door and Message Central begins the TTS message "The Front door has been opened" BUT Welcome Home has also hit its 10 second delay and immediately interrupts Message Central's announcement cutting it off and then playing Welcome Home. Basically the two apps conflict each other quite often.
So is there thoughts of maybe creating a virtual TTS driver that would accept incoming messages from any app or HE and then speak them with a delay/pause between each queued message?
My view.
All of these are great!
But they overlap... you should use the one that it's more suitable to your needs only.
Or
You should plan your routines/rules in such a way they don't overlap.
I think this is feasible but the most difficult part would be determining the spacing between the announcements. For example,
TTS 1 - short phrase
TTS 2 - long phrase
TTS 3 - very long phrase
Since the announcements can be strung together in many different orders, how would you determine the schedule to send them to the speaker. You could end up with the same issue if the spacing is too short or very delayed messages if too long.
The talent in the community is well beyond me so I hope someone can think of an imaginative solution. Counting words in the phrase maybe?
That doesn't work as a solution as each app and even your RM rules are independent of each. Also each offers things the others don't.
You also get this issue in an existing app too.
Example:
Using JUST Message Central if you open/close door message will be sent to speaker. During message if you open/close door then the current message is interrupted and a new message is announced.
What I am proposing is a TTS queue. Meaning as messages want to be announced you queue the messages and play in order as requested with a certain delay between them.
@stephack Not really thinking of using TTS stringed together into a single TTS but rather a queue that would announce in order accordingly. I guess the biggest issue like you said is how do you determine the pause before sending the next TTS message. That is a good question.
I think there could be an app that you connect to your speaker. Then a virtual tts speaker device that talks to this app. Any tts sent to the virtual tts speaker would go to the app.
The app would queue the tts commands in order of receipt. The length would be set by calculation based on number of text characters plus a buffer (I have seen this before in TTS apps).
That's what I understood from you OP. By "strung together" I was referring to the queues order. Essentially they would have to be scheduled based on time. So each message would be scheduled based on a best guess of the time it takes to get the mp3, play the message and insert a pause.
TTS2 = time to process mp3 for TTS 1 + time play message for TTS 1+ pause time.
TTS3 = TTS 2 + the same calculations for the second message.
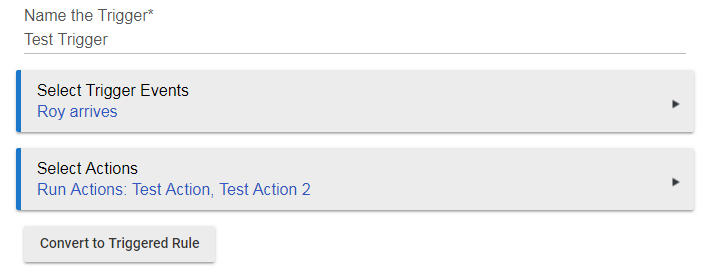
@Royski does that app allow queuing of TTS messages? From what I read, it seems to allow creation of a virtual group of speakers, but I didn't see reference of message queuing. Might be a better question for @Cobra
Yeah I think you're correct, I was getting mixed up with Echo Speaks.
That said, can they not be defined as Actions in RM, and then a rule to trigger those actions (presuming the actions will be executed one after the other?)
The Actions would be the required messages.
The issue would be controlling the timing of each message. If 2 messages are received, the second would cut the first short....so each message would need to be timed perfectly to avoid that but also not leave an unnecessary delay between them.
@djgutheinz mentioned that this has been done with other apps. Do you remember the name or can you point us in the direction. No need to reinvent the wheel is someone already has done the hard work.
Below is code from my Samsung Multiroom Speaker driver. I had to create a special TTS capability (could not get the native to work as expected). And even better, the return from textToSpeed is a map that includes the test uri plus the duration. So no calculation is necessary. The issue is how to make the queue work:
method: processTTSinput - called from the device with the new TTS map (uri, duration). Places the data into a store for play. Calls processQueue method sending "processTTSinput" as an input.
method: processQueue - called from processTTSinput and playTTS methods, using passed methodId. If method Id = processTTSinput and state.playing = true, adds to queue then exits. Otherwise, it will process the next TTS in the queue and send it to playTTS. After processing the queued TTS, removes that TTS from the queue. If queue is empty, exits.
method; playTTS. Called from processQueue passing uri, duration. Sets state.playing = true. Plays tts and uses a pauseExecution = duration + 2 seconds. After pause, setplying set to false and calls queue method passing "playTTS".
def textToVoice(text) {
// Command in-lieu of textToSpeech (since TTS does not work for MS Soundbars)
def uriText = URLEncoder.encode(text, "UTF-8").replaceAll(/\+/, "%20")
def trackUri = "http://api.voicerss.org/?" +
"key=${ttsApiKey.trim()}" +
"&f=48khz_16bit_stereo" +
"&hl=${ttsLang}" +
"&src=${uriText}"
def duration = Math.max(Math.round(text.length()/12),2)+1
def track = [uri: trackUri, duration: duration]
return track
}
@djgutheinz Great work Dave! You are a very talented developer and I truly appreciate this work. Any chance this code can sit on your GitHub for others who might want to use it as a baseline to incorporate other speakers (Sonos, Echo Speaks, etc)? I only use a Samsung M3 for all announcements so I have been very blessed with this code.