Still is mine by and large. I find it so much easier to install, configure and manage services on bare metal Linux.
3 Likes
Each to their own. I virtualize and containerize anything that remotely makes sense to, which I find is most things.
It was definitely a lot more work initially, now it is a trivial effort most of the time.
2 Likes
I think they can seem complicated if you don't have experience with them, but once you have some familiarity it's pretty straight forward. FWIW, you don't need port forwarding, and I almost never use it. I use the native host network instead.
To answer your question, docker containers retain state across restarts. So when you restart a container, it will use the same image as the previous instance. You have to take explicit action to have the container use a new base image.
1 Like
So keeping updated is more complicated as well then? Right now I just run apt update/upgrade to keep updated. If I had influx and grafana in containers I would need to check for updates on each one and then update the base image. No thanks. Updating PITA was why I setup a VM and moved off my original windows setup.
Your example of running it on a NAS is a perfect example of where it is useful. I assume the OS on the NAS does not play nice with it natively, Or may not allow you to install things to prevent breaking the OS.
1 Like
No, not really... There are tools to do it automatically (watchtower, et al), or you redeploy the container and simply tell it to pull current image. Actually less steps/typing than apt update.
But each to their own. I'm not trying to "convince" you. There is nothing wrong with how you are doing it today if that is working for you.
EDIT: I guess I should backtrack a bit - how you update a container/stack varies depending on how you built it or if you are using a prebuilt one.
1 Like
I’m running a few things in containers on my NAS too and that’s why I’m using them.
It's really not complicated. If you do everything by hand, the steps are:
- docker pull [image]
- docker stop [container]
- docker rm [container]
- docker run [container]
The essential diff from apt steps would be having explicit stop/rm/run rather than restart.
If you are OK with automatic updates you do this once, and never look at it again:
docker run -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower

Or if you are a manual update kind of person, just add a --rm and --run-once to it....
docker run --rm \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower \
--run-once
Voila. Every container on the machine updated.
Or if you only want to update a specific container, add that to the end of the command:
docker run --rm \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower \
--run-once \
<container name>
Either way, it is literally a one command copy paste.
4 Likes
So I finally managed to get this working, using Maker-API, NodeRed, InfluxDB v2.4.0, and Grafana 9.1.6.
I made a few modification to my existing InfluxDB 1.x flows in NodeRed and going from a single hub to 3 hub model, I managed to get all 3 of my hubs reporting in using the same flows into a single database so I'm seeing all my data. The biggest hurdle was accessing the data within Grafana and being able to create the graphs using the InfluxQL query language. To do that I followed the instruction from @jtp10181 above to use the cli to create a dbrp for each database (IoWatta and Hubitat), and I created 2 usernames, one for each database. With those created, I went back into Grafana and created new datasources that look like this:
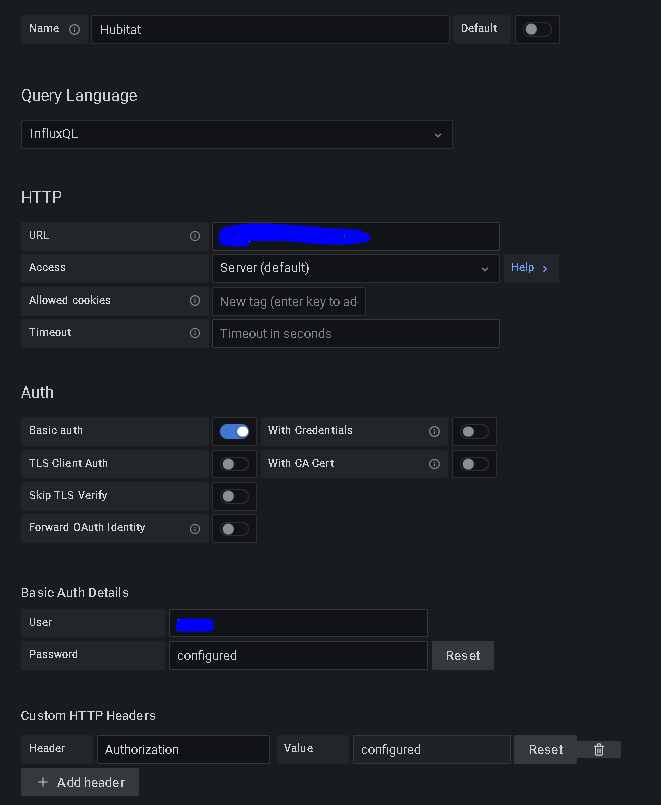
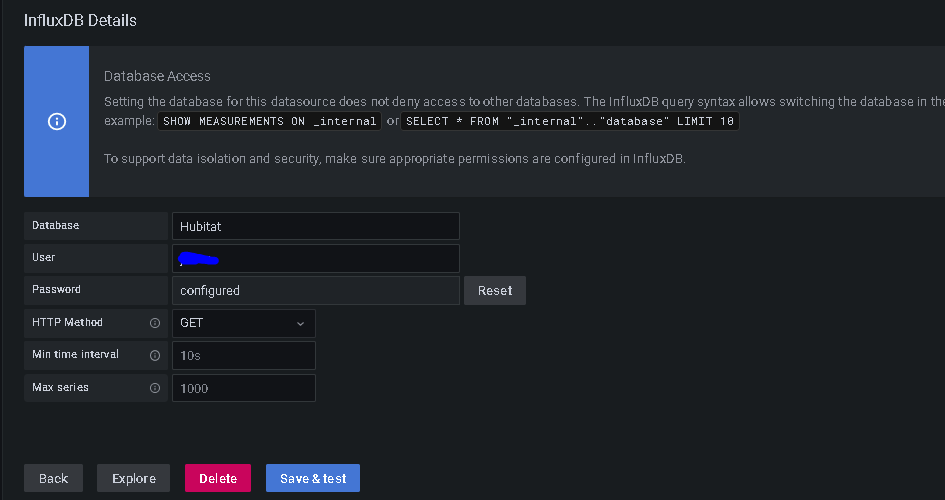
Username = the username you created in the steps above that match the database along with the password you set for that username
You have to add a custom HTTP header with the Header as "Authorization". In the value, you have to add "Token " as the value. The key is you have to have the word Token with a space after and then the operator token value. If you don't include the word Token it won't work.
Hope this helps anyone else who's trying to figure this out.
2 Likes
Wo, shows how far behind I am on my rpi... I think I'm running 7....
Great instructions. This worked for me as well. What does the "--default" parameter specify when implementing the dbrp? Thanks!
From the docs:

OH man back home and beat, two conference in two weeks. Ready to setup the integration for next weekend.
I missed this thread, but I did some heavy modifications on the InfluxDB app to add support for v2. I ended up making it an option in the UI, so you can use this with either v1 or v2. In the end, I went back to v1.8, so I haven't used the v2 implementation recently, but it should work.
1 Like
Oh man I just got the "shim" working a month or two ago with V1 calls to store data in a V2 DB. I will give this a shot.
I can vouch for that working well. It actually uses a little bit less cpu then then original. I forked it a while back and tried to get the updates it added to the community Influxdb app, so far no success though.
As noted in the PR discussion, there is a bunch of stuff in the PR, most of which doesn't pertain to InfluxDB 2. If you can break the PR up into targeted changes, or simply remove all the other stuff, it's a lot more likely to be reviewed. Confirmation of backward compatibility for existing InfluxDB 1.x installations is also required.
I just reviewed the code chnages I submitted. I will break it out into parts as to only do one thing at a time. I believe i closed my previous pull request and have now submitted a new request to start the process for each part. I will send the next update when this is merged.
Comments in the PR.
I made the requested change.
1 Like

