I am using something similar in my drivers to store dynamically compiled preferences options per device model / firmware version, using a ConcurrentHashMap. Doing it so they only have to be generated once then pulled from the variable after that. Your implementation looks slightly more advanced and I see where each app instance will be separated in the variable using the appID which is what you need.
That would be my use case too. Keep the custom stuff in a separate instance.
2 Likes
I made a few changes based on my tests.
- The queue and mutex now stored in a ConcurrentHashMap instead of Map
- Added cleanup on uninstalled()
- Along the way, learned that the code declaring the @ Field static variables gets executed every time new code is saved for the app. So I believe the risk of data loss when new code is saved (i.e. queues not empty at time of code save) exists even in the current version of the app.
- Moving the app instance specific queue and mutex to state (or atomicState) appears to be a no-go : the State object behaves like a Map (as per documentation) and value type info seems to be lost for these objects. I could not figure out a way to cast them back to their actual type when retrieving them from the State.
Still plan to test this a bit more aggressively, subscribing to lots of devices and events across multiple apps and see how it goes.
As I notice many apps use this sort of pattern (collect event data from multiple devices into a single data structure) I wonder if it can/should be moved to a Library, with proper test harnesses, etc.
Feedback/suggestions more than welcome.
I dunno if the self-hosted InfluxDB tools are different, but in the cloud-hosted version, you can almost always solve this issue downstream, in InfluxDB or Grafana. For continuous data, it may only take a couple of lines of flux code to push a transformed data stream with the last known state duplicated at the end. For discrete data, like switches for example, the UI provides options to interpolate "step-forward" these (the selected option in this screenshot) :
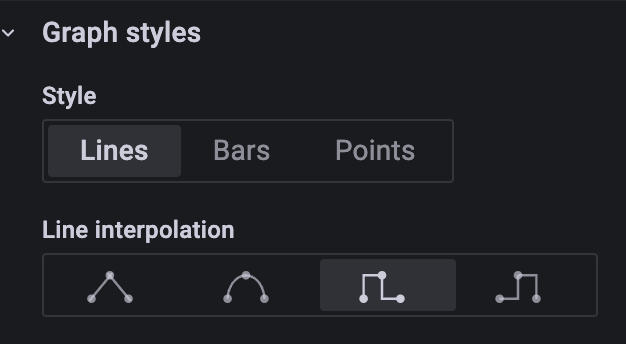
This should allow you to leave your OG data pristine yet get your graphs to adapt to any time scale.
Although I understand how it can be helpful in practice, I'm not a fan of filling in missing data points with soft polling. Those points are not actual events yet they are inserted into the data stream just like true events (maybe they should be tagged differently, now that I think of it). Also keep in mind the lack of data is... data, in a way. Did the device's battery fail? Did it drop off the mesh? etc.
Well I think one may need to think of this not as looking at events, but looking at the current reported state.
Think of it like this if i want to monitor the temp in a room does it matter that the device hasn't reported or that i just know the last state of the temp. Personally the temperature of a room is the temp of a room. just because it isn't reported doesn't mean it doesn't exist. So if i want that to show up every 5 min so i can graph it well then that makes sense.
There are some kinds of events though that I agree soft polling doesn't benefit from. That is why the idea of breaking this stuff out is appealing. In the grand scheme though a few items here and there won't change the impact much. Especially after some of the performance improvements @dennypage got in the last release of the code.
I am going to see if I can remember how to build a child app and then pull the soft polling out to be independently configurable and submit the events to the main app.
Of course. My point is that the attribute value being polled, strictly speaking, is only valid at the time of the last event. Who knows what the temperature has been since the device last sent an event (maybe the sampling rate is low) ? You, as a user, can usefully make the assumption/approximation that it hasn't changed since, but I prefer to make that assumption in the data processing step (InfluxDB) than to commit it in the measurement stream as though it was known at that time. IMHO the measurement stream should remain representative of the event stream and avoid mixing it with state information.
Agreed.
I think this depends on the device and a users use case. but we can agree to disagree.
I have a working child app that can break out the polling into separate apps. Simply put the child apps are independently configurable with their own polling intervals and device configuration. They load data into the main apps logger queue, so it still handles all of the posting to the database. The thought is this should help control the number of posts to the database. For maximum efficiency. Let me know if anyone sees benefit this could be dropped into the current code base easily.
1 Like
Hi, how can I find these?
If you use HPM you can do a matchup / update. If you want to install manually here is the github site:
1 Like
The idea of breaking this out into child apps doesn't seem like a very good one at this point. My initial testing is showing that will double the time it takes for each poll event to be handled and that isn't good depending on the number of devices you have. going to keep looking at it.
1 Like
FWIW, when I was talking about parent/child previously, I was intending that all event and queue processing would still happen in the child. The parent would not be involved in the data path, and the children would have no shared state amongst them. Another way to say this is that each child would have their own private mutex and loggerQueue.
The parent would only be responsible for initially setting up the child, and potentially cleaning up after a child if it is removed. It's really a convenient mechanism for grouping applications of the same type together, while allowing them to each have individual configuration. Most of the built-in apps are constructed this way. Basic Rules, Notifications, Rule Machine, etc.
1 Like
Well probably for good reason. I am seeing some loss of performance when having the child apps interact with the parent to load the queue. Translates to a few ms each way. I just adjusted a few things and it did improve for the soft polling, but didn't make a difference at all for event based tracking child app I have. It is probably a small difference overall at this point though.
Really my only thought with using the parent app was to keep the posting to InfluxDB in one spot to try to keep that process as fast as possible. I wasn't thinking about multiple database as that is what @hubitrep seems to be working on.
That is a common use case for Child/Parent apps, but i have used it both ways in the past on Smartthings.
In the Paradigm I was working on the Parent app has all of the setup to talk to the InfluxDB Database, Manages writing to the DB and those respective settings and would handle Hub tasks.
The child apps would simply handle the events that either need to be generated for polling, or process from subscriptions, and allow for seperate input options and settings for those devices. The soft polling cold have different types of devices and different intervals with custom or non custom attributes. The Event monitoring jobs would have the ability to decide between Custom or standard attributes and then select what you want to send.
I just wish there wasn't the impact of a few ms when passing the values to the queue in the parent app.
Also not sure why but my initial testing with the @hubitrep code was causing even more slowdowns. Not sure what the deal was with that, but it was even more impactful to performance. But i need to do further analysis on that
I've just submitted a new PR (don't worry I think I'm done for a good while). Solves the issue from my standpoint, by adding a column in the measurement that indicates whether the event was soft-polled or not.
That closes the whole soft-polling discussion for me (at least) as I can now filter those soft-polled data points (or not) in either InfluxDB or Grafana, depending on my use-case (still need that filterEvents option exposed though ![]() ). I am okay with grouping devices together into an app instance based on polling preferences (I will have few groups) even if that means I might end up with more than one app instance per db connection. I don't think it's going to be a big problem honestly.
). I am okay with grouping devices together into an app instance based on polling preferences (I will have few groups) even if that means I might end up with more than one app instance per db connection. I don't think it's going to be a big problem honestly.
Acknowledged. I have no idea other than maybe the ConcurrentHashMap synchronisation is slowing things down somehow.
I like this idea a lot.
The problem with making the parent child relationship that way now is how do you do it and keep compatibility with current installs. I don't think you can. It would require a complete restart for everyone as they would have to install the child app once they upgrade.
1 Like
Perhaps that's the reason why some apps end up getting renamed (even built-in apps like RM, or Thermostat Scheduler for which the old version was renamed "legacy"). Allows people to decide what they want to do but it does add a bit of work when transitioning. I wonder if it would be possible to export the app running the current version, then import it in the (new) child app? I don't have an opinion on whether this change warrants something like that.
Appearently there is a addChildApp method. Not sure how usable it would be to help with a migration to a parent child setup though. I have never tried it and this is the only mention I can find of it.
maybe this
addChildApp("mynamespace", "my app", "My app label", [settings:[var1:["type":"bool", "value":true]]])
Please have a look at this PR. It moves the queue into the application state and allows multiple instances to be installed. Note that this requires Hubitat 2.2.9 or above, and will be reflected in the package manifest when published.
Unfortunately, I was not able to figure out any way to migrate any pending but uncommitted updates. Fortunately it's a one-time loss.
As @hubitrep discovered, a new loggerQueue was being created each time that the application source was being written, so the loss of pending data was already happening. I had never noticed. On the plus side, with the move of the queue into the application state, pending data should be preserved when doing future updates.
I don't know of any way for a parent app to adopt an existing application its child. I believe moving to full parent/child would require introducing a (completely) new version of the application.

