It's the reboot. There are no performance focused changes between the two minor versions. We got more of those in the pipeline for 2.2.3, but they aren't live yet.
10 Likes
Thanks so much for the info. I really appreciate it.
LJ
Although I wasn't having any apparent slowdown issues, this update sure seems like it makes everything more "snappy" than it has been in a while. Everything just seems smoother and more responsive.
2 Likes
UPDATE: 36 Hours since last restart/reboot. Things were totally clear until about 3:30M ET. At that time it looks like Zigbee started to slow down and has continued to get worse, while Virtual and Z-wave still seem stable.
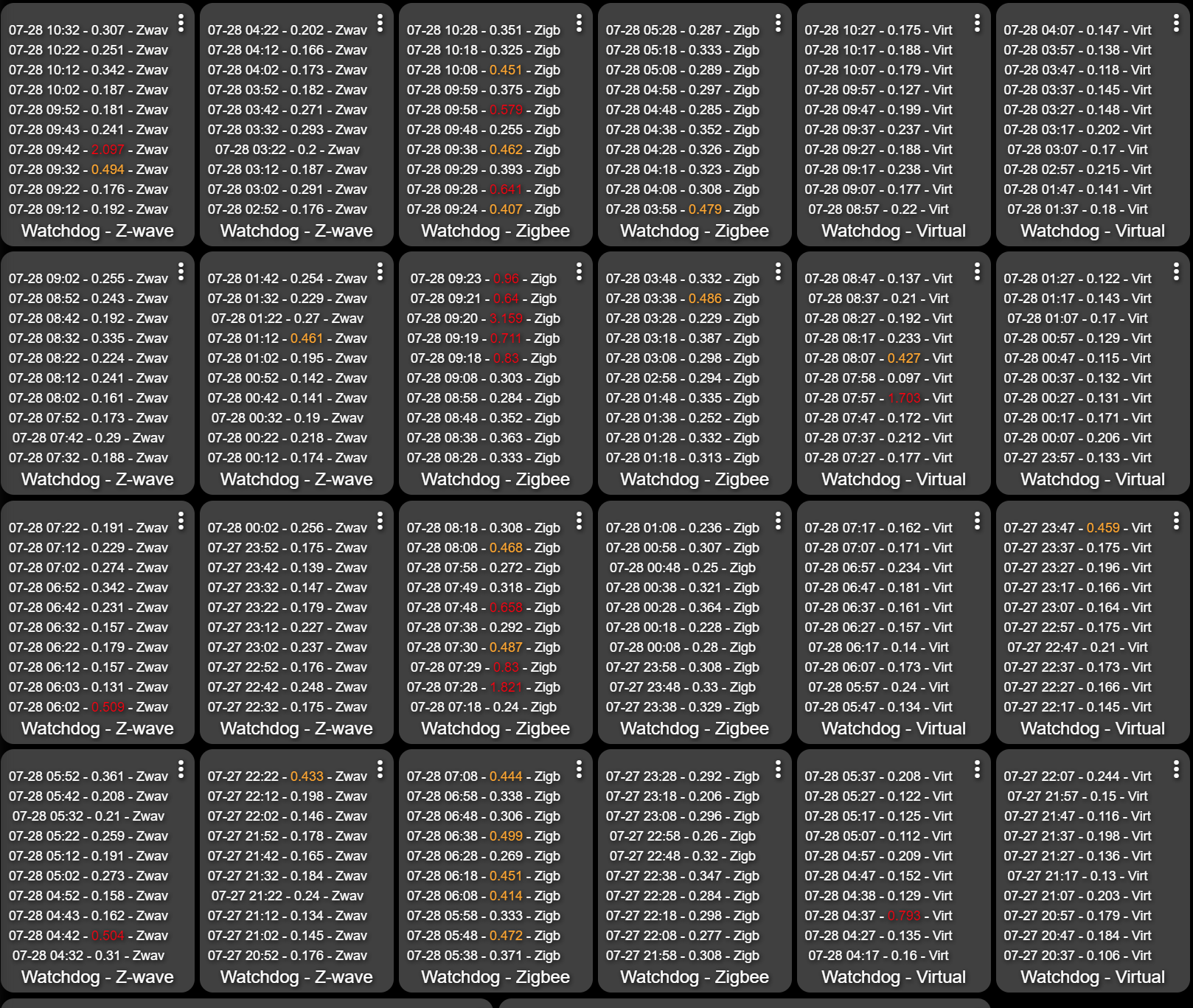
LJ
UPDATE: @gopher.ny OK, so some interesting observations. The system was reasonably stable through the day yesterday. there were a few increases in periodic slowdowns yesterday during the day but not enough to force an automated restart.
Then maintenance ran. I have Hub Watchdog set to stop during the maintenance period from 1:50 AM to 2:50 AM. That was always long enough and the restart and DB Stabilization period usually took about 10- 20 minutes. The watchdog shows that after the hour maintenance hold, the system continued to be in Slowdown and ultimately restarted the HE processes around 3 AM. The restart happened, and as you can see below, the system continues to be in a slowdown in Zwave, Zigbee, and Virtual watchdogs. it has not restarted but it is close.
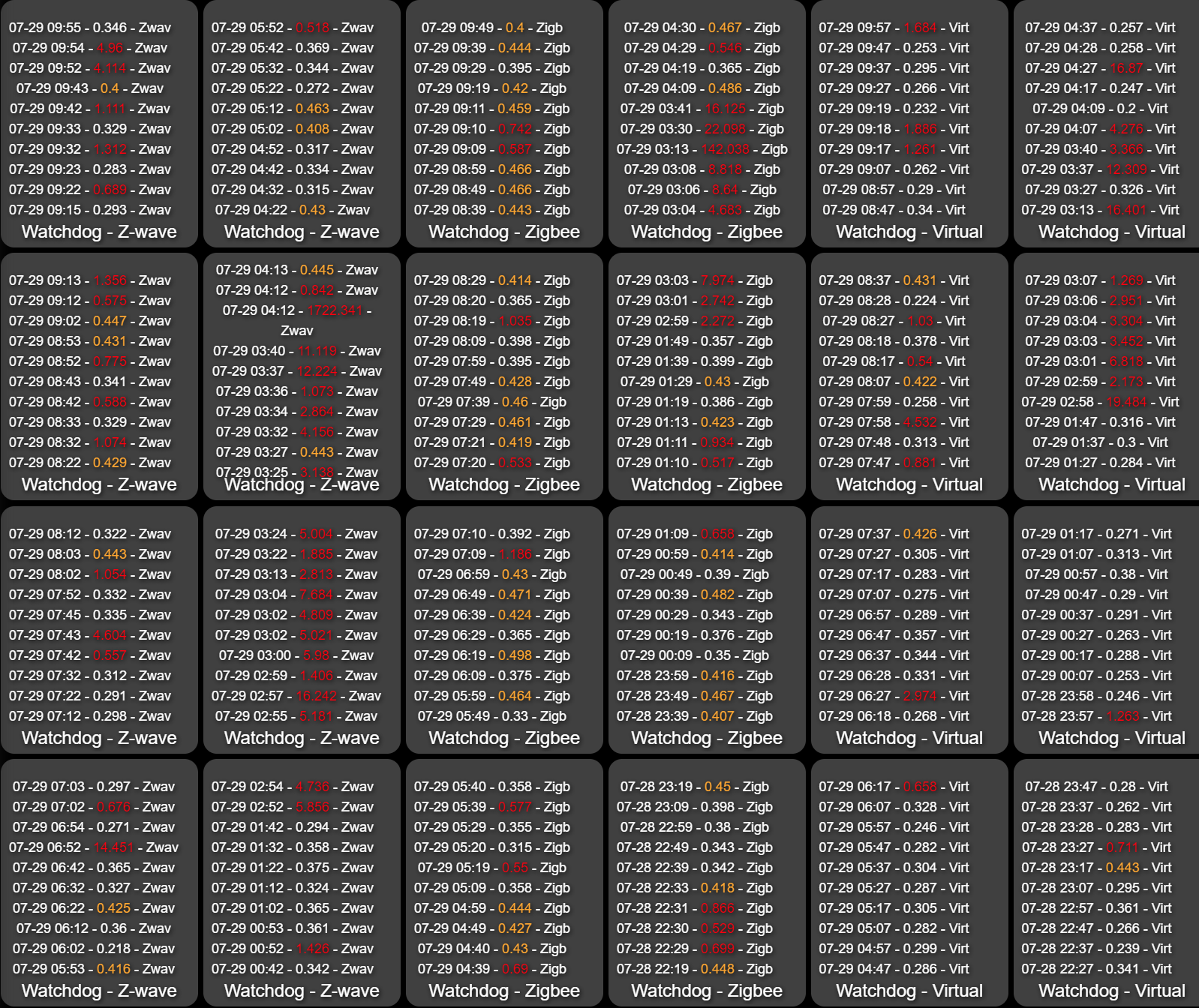
I have suspected in the past that something in the maintenance may be triggering some slowdowns, but this 2.2.2.129 seems to be taking significantly longer to stabilize after maintenance than previous versions. Is it possible that nightly maintenance will be that much longer in this series of point releases? Is anyone else seeing this too?
LJ
1 Like
I also often suffer from this type of performance degradation at the nightly maintenance period. The fact the nightly process can so seriously affect hub performance like this is really ridiculous in my opinion. Many a time my lights just didn't respond at all. When someone breaks their neck falling down the stairs at night I wonder how the value proposition of "local, fast" will stand up. Hubitat really need to find a way to resolve this, and the absolute minimum should be to be able to select the time when this irritating service interruption occurs.
3 Likes
....this.
2 Likes
If you can let me know whether your burglar alarm is Z-Wave or Zigbee then I can work out if I have 28 minutes or 2.36 minutes to get in and back out with your stuff before your system responds and exactly at what time to make my attempt.
Thanks.

4 Likes
I don't have an issue with a certain amount of slowdown during maintenance as it is understandably memory or CPu intensive. 10 - 15 minutes would seem acceptable. but not an hour or two.
Worse is that it seems to sometime never recover from the slowdown during maintenance until a restart is performed. That would seem to be unnecessary if things were all properly executing and completing. It seems like every 2 or 3 times maintenance runs it doesn't complete everything, or at least doesn't do anything to correct the slowdowns already happening, perhaps.
LJ
My alarm system is not dependant on HE and has multiple redundancies, but I can monitor it from HE. I guess I will need to keep my eye on YOU now! LOL 
2 Likes
Version 2.2.3 (next beta) has faster/less resource intensive event cleanup. That should help. But there may be some radio related stuff going on, too, and that is going to be a lot harder to reproduce and deal with.
14 Likes
FYI, I have slowdown issues too and IMO it has nothing to do with the radios. Many people are focused on how fast devices react whereas I have taken a simpler approach. Example; Setup a rule that loops from 1 to a 1000 and store the loop count in a local variable (giving it something to do). Time when the loop begins and ends. It is a very simplistic test that only focuses on how fast a rule can process a task, whatever it may be. I suspect the slowdown is not in the radios but how fast commands are being sent out and how long it takes to process events. And as I have said before and many are saying the same thing. Everything runs great for some period of time and then in a short period of time a noticeable drop off in performance, and if allowed to continue that performance eventually grinds to almost a total halt. Again, as others have said the maintenance period is reasonably short until the slowdown which makes it drag out longer and longer until you wake up in the morning and it still hasn't finished.
4 Likes
After thinking about this statement I am not sure I agree. Doesn't the data From Hub Watchdog on the Virtual Switch show that even functions that don't involve the radios have slowdowns? In fact, if you look at the past data i have provided, it often looks like the Virtual Switch test begins to show slowdowns before the Zigbee, and certainly before the Z-wave. As @an39511 discussed above, if you just look at tests that don't involve the radios, there is significant slowdown evident.
Would radio queue issues slow down the rest of the system which doesn't involve the radios that much? Shouldn't we see the radio devices slowing down before the the non-radio tests if that is the case?
LJ
Thanks for doing this. Hopefully this can help us get to the bottom of the slowdown issues in certain cases. My hub could be fine for weeks, and then, without any changes, the slowdown shows up.
1 Like
Just to throw my two cents in here:
I too experience the slowdown issues, usually after 36 to 48 hours.
One common theme I see in these threads is people with open dashboards. I have a tablet mounted in the bathroom to allow us to monitor and control hot water re-circulation, water temperature, etc.
Taking a closer look at the dashboard code might be worthwhile. I seem to recall the slowdowns started for me very shortly after 2.0 was released (Like maybe 2.1). I definitely never had any slowdown issues before that.
1 Like
Don't know if dashboards contribute to slowdowns but I don't make use of devices running open dashboards. I only use dashboards on my phone in the rare case I have to override some automation or there is something wonky I need to deal with. I make use of them maybe 2 times a week if at all.
I haven’t used dashboards until the last month or so. I’ve been having the issue since at least 2.0
I have always used dashboards and currently use dashboards inside the great app Hubipanels. I have three panels running various dashboards. the way the app works is that it loads all the dashboards at once on the tablet and keeps them updated. It then provides a menu system and rapid dashboard switching, with badges on each menu item which reflects the number of on devices. It great, and earned more WAF points than anything I have done in terms of automation. I have been using dashboards without that app since migrated to HE. this is the best solution I have found. My wife wouldn't have accepted or adopted all this hobby without dashboards.
I can't say when the slowdowns started but it has been pretty much since I migrated. It was always blamed on Echo Speaks back then, but i was using dashboards then too, and echo speaks seems to have been excluded from the suspect list over time. I and others did try deleting echo speaks and still had slowdowns.
For me, I support digging into everything including dashboards and I am willing to work with whoever might request it at HE development who might want to use my setup for data and/or testing.
LJ
If looking at the dashboards it would be good to note if you are using the cloud or the local links and the number of devices you may have approved for the dashboard.
I believe the cloud and local dashboards query for events and updates differently.
And the more devices you have approved on the dashboard would put more strain on the hub at each query.
I have a tablet running 24/7 but I’m not sure if it actually disables the dashboard refreshing when the screensaver is running (which is most of the time).
Just a couple of ideas to throw out there if you are focussing on the dashboards.
1 Like
In my case, my panels are all local network at this point. I occasionally use the HE app on iPhone remotely through the cloud, but these days, with COVID I rarely have need for that.
As far as the number of devices, i have many on the panels. While I get that the more devices the more the system usage, but that would not seem to explain that this lasts 24 to 36 hours without issues, and then starts to degrade rather quickly. the panels are on all the time and Hubipanels keeps them updated all the time. eve if a queue fills up and then causes slowdowns, the time period for the queues to fill up should be consistent, and it is not. the time frame varies for me from 24 hours to 48 hours before things get crazy. why would that vary. Usage perhaps? still an issue for dashboards, I would suspect.
LJ

