That is an excellent point - right tool for the right job. You still need a centralized place to coordinate everything and in your case (and mine) it looks like Node-RED but others may only be using HE.
It would still be interesting to have some watchdog features built into HE and accessible through HSM or some other though - testing for individual devices, services, HE resources, possibly other HE hubs on the network etc and react in a standardized way. Coupled with a possible "monitoring" service provided as an addon to one of HEs subscriptions and you are mostly there..
I started out with humble beginnings with this topic, but am certainly enjoying the ride...
I think you make a good point @martyn, "right tool for the right" job as @erktrek summarised, is what most (if not all) users should aspire to, particularly as your setup becomes larger and more complex. The choice of taking on a hub like Hubtiat reflects people wanting to move into more mature HA than just smart lighting or some simple routines from a smart assistant, and some of the monitoring solutions you list reflect a similar progression in that space.
For me, while I came at this with my work-related software developer / IT support hat firmly on, which leans towards that more enterprise level solution, I do also accept that it needs to be a layered approach in order to satisfy the different requirements of HA users. As a developer of a driver or app in HE, I can only provide a certain level of information on the interactions I have with the devices or services I interact with. What is done with that information, what other information may provide a more accurate picture of system health, and how all of that information is interpreted is something that requires architecting. For some HA setups or some people all they require is a simple indication of the status of a small number of key features in their HA setup, and so some basic indicators on a dashboard or inside a rule may be enough. Others have a much bigger setup that requires a more coordinated, centralised and sophisticated monitoring and alerting system.
I guess the point I am making is that at a basic level, any information on the health of a device or service from within, typically, device drivers, should at least be present in a consistent way, that benefits both the smaller and simpler setups, as well as the more complex and sophisticated setups.
EDIT: Reading my comments back, I know this sounds like I am almost arguing against your point @martyn, that is not what I intended. I think their are different levels to which you can take a solution in this space, and for some that includes those more tailored solutions like you mention. As you step up the complexity of your HA setup the pay-off for investing the time and/or money in those systems is easy to see.
I feel I have some interesting points to mull over, thanks for those that have contributed so far... Feel free to add to these, would love to hear more ideas in this space.
Was bored this afternoon, so was flicking through rpi projects online and saw one for Nagios, so am thinking I will take a look at it on my dev rpi, maybe this afternoon. Seems simple enough to get started, but I'm sure there's a long rabbit-hole waiting for me.
I had made tentative steps to transition some of my ping testing from HE to Node RED, partly as a way to start using Node RED, but also to shift some of the processing for my monitoring off my HE hubs. I'm thinking now Nagios is more likely the place to move those activities, and leave Node RED for some other project. It was also good to get confirmation of others using it to monitor their setup.
Haven’t looked at Nagios for several years, but from what I remember it will do some pretty in depth monitoring if you spend the time to configure it right and put the agents in place. If you’re going to venture down that rabbit hole take a look at Zabbix too.
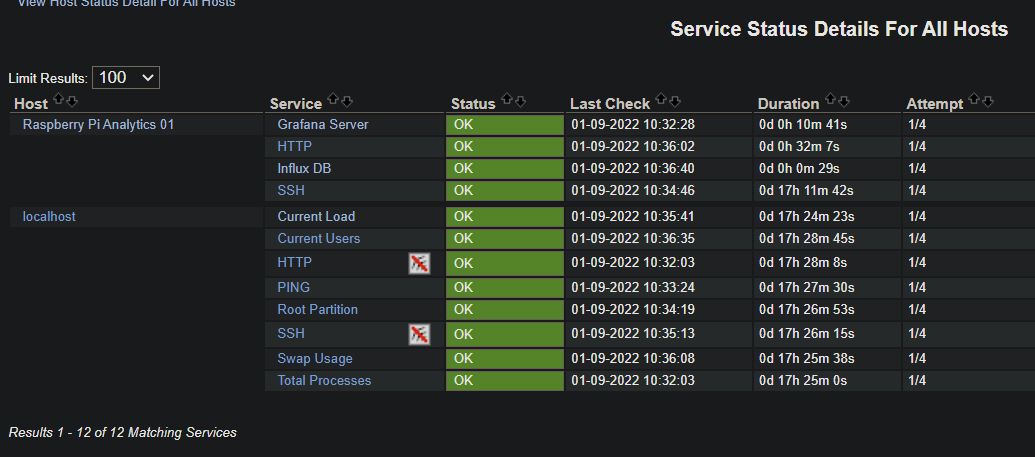
Not bad for an afternoon and morning's work. Got some of the basics setup relatively easily with ping and SSH checks, then local resource status', plus Grafana and InfluxDB on a separate rpi. Very happy.